|
| |
|
|
|
| |
| |
| Introducción. |
| |
Existen
los llamados sistemas de bases de datos centralizados, donde
todos
los componentes del sistema residen en un sólo sitio físico.
Cuando decimos componentes, nos referimos a los datos, el software
de SGBD y los dispositivos de almacenamiento secundario asociados.
Quizás haya acceso remoto a esta base de datos a través
de terminales, pero los datos y el software siempre residen en un
solo lugar. En los últimos años se ha notado una clara
tendencia hacia lo que denominamos sistemas de bases de datos distribuidas
(SBDD). El software con el que se implementan se denomina sistema
de gestión de bases de datos distribuidas (SGBDD). El objetivo
del presente trabajo práctico será la explicación
de cuáles son los objetivos, las ventajas y desventajas,
y el modo de optimizar consultas en bases de datos distribuidas. |
| |
| CONCEPTOS
DE SISTEMAS DE GESTIÓN DE BASES DE DATOS DISTRIBUIDOS |
| |
Una
base de datos distribuida es una colección de datos que pertenece
lógicamente al mismo sistema, pero que está dispersa
físicamente entre los sitios o nodos de una red de computadoras.
Entre las ventajas potenciales de un SBDD están las siguientes: |
| |
La
naturaleza distribuida de algunas aplicaciones de bases de datos:
Éste
es el típico caso de una compañía que tiene
oficinas en diferentes ciudades. Es natural que las bases de datos
estén distribuidas en diferentes lugares físicos.
Existen los usuarios locales, que solamente realizan consultas sobre
los datos que están en un lugar, pero también existen
los usuarios globales, que indefectiblemente deberán pueden
requerir acceso a los datos almacenados en varios lugares diferentes. |
| |
Mayor
fiabilidad y disponibilidad: La
fiabilidad se define como la probabilidad de que un sistema esté
en funciones en un momento determinado, y la disponibilidad es la
probabilidad de que el sistema esté disponible continuamente
durante un intervalo de tiempo. Cuando los datos y el software están
distribuidos en varios sitios, un sitio puede fallar mientras los
demás siguen operando. Esto mejora tanto la fiabilidad como
la disponibilidad, mientras que en un sistema del tipo centralizado
si hay un fallo es el sistema completo el que deja de estar disponible.
Se logran mejoras adicionales, si se replican con un criterio adecuado,
los datos y el software en más de un sitio. |
| |
Posibilidad
de compartir los datos al tiempo que se mantiene un cierto grado
de control local: Hay
algunos tipos de SBDD que hacen posible controlar los datos y
el software localmente en cada sitio, a la vez que los usuarios
de otros sitios remotos pueden tener acceso a ciertos datos a
través
del software de SGBDD. |
| |
Mejor
rendimiento: Como
la bases de datos están divididas en pequeñas bases
de datos en cada sitio que conforman el total, las consultas locales
y las transacciones que usan un sólo sitio tienen mejor rendimientos
porque las bases de datos locales son más pequeñas.
Además, cada sitio tiene menos transacciones en ejecución
que si todas se enviaran a un solo sitio centralizado. Si se efectúan
transacciones en más de un sitio, pueden efectuarse en
paralelo para reducir el tiempo de respuesta. |
| |
La
distribución
produce un aumento en la complejidad del diseño y en la implementación
del sistema. A continuación se detallan algunas funciones
que el SGBD debe agregar a las que realiza un SGBD centralizado: |
| |
|
Acceso
a sitios remotos y transmisión de consultas y datos entre
los diversos sitios a través de una red de comunicaciones.
- Seguimiento
de la distribución y replicación de datos en un
catálogo del SGBDD.
- Elaboramiento
de estrategias de ejecución para consultas y transacciones
que tienen acceso a más de un sitio.
- Decisión
sobre qué copia de un elemento de información
replicado se podrá acceder.
- Manutención
de la consistencia de las copias de un elemento de información
replicado.
- Recuperación
de caídas de sitios individuales y de fallos de enlace
de comunicación.
|
En
el nivel físico, o de hardware, los principales factores que
distinguen un SBDD de un sistema centralizado son las múltiples
computadoras, llamadas sitios o nodos y que estos nodos deben estar
comunicados por medio de algún tipo de red de comunicaciones
para transmitir datos y órdenes entre los sitios. |
| |
Los
sitios pueden estar relativamente cerca físicamente, por
ejemplo, dentro de un mismo edificio, entonces estarán conectados
a través de una red de área local. Otro caso es que
estén distribuidos geográficamente a grandes distancias,
para lo cual se usarán redes telefónicas o satelitales.
A veces se utiliza una combinación de estos dos tipos de
redes con diferentes topologías. |
| |
El
tipo y la topología de la red empleada influye en gran
manera sobre el rendimiento final del sistema y sobre las estrategias
para
el procesamiento de consultas. |
| |
| APLICACIÓN
DE LA ARQUITECTURA CLIENTE-SERVIDOR |
| |
|
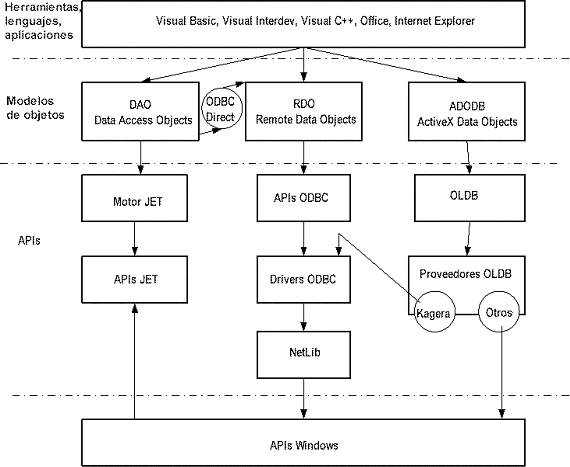
La
arquitectura cliente-servidor se está incorporando cada
vez más a los paquetes de SGBD comerciales conforme se
van orientando a la distribución. La idea es dividir el
software de SGBD en dos niveles -cliente y servidor- para reducir
su complejidad. En la figura anterior se ilustra como algunos
sitios pueden ejecutar exclusivamente el software de cliente (sitio
1 ó 2), mientras que otros podrían ser máquinas
servidoras dedicadas que ejecutan sólo el software de servidor
(sitio 3). Algunos sitios más podrían manejar módulos
de cliente y servidor a la vez. Aunque hay varios enfoques para
arquitecturas cliente-servidor, una forma de interacción
entre cliente y servidor podría efectuarse como sigue durante
el procesamiento de una consulta SQL:
- El
cliente analiza sintácticamente la consulta del usuario
y la descompone en varios consultas de sitio independientes.
Luego las envía al servidor apropiado.
- Cada
servidor procesa la consulta local y envía la relación
resultante al sitio cliente.
- El
sitio cliente combina todos los resultados recibidos y produce
el resultado de la consulta original.
|
En
un SGBDD se puede dividir los módulos de software en tres niveles:
el software servidor, que se encarga de la gestión local
de los datos de un sitio. Luego está el software cliente,
que se encarga de las funciones de distribución teniendo
acceso a información almacenada en el catálogo del
SGBDD para procesar solicitudes que requieren más de un sitio.
Por último, el software de comunicaciones proporciona las
primitivas de comunicación con que el cliente transmite órdenes
y datos entre los diferentes sitios. |
| |
Otra
función que está a cargo del cliente es la de asegurar
que las réplicas de un elemento de información sean
consistentes, para lo cual se vale de técnicas de control
de concurrencia distribuidas. El cliente también debe asegurar
que las transacciones globales sean atómicas realizando acciones
de recuperación globales cuando algún sitio falle.
Un cliente puede aparentar transparencia de distribución
permitiendo al usuario escribir consultas como si la base de datos
fuera centralizada, sin tener que especificar los sitios donde se
encuentra la información. El SGBDD mismo registra los sitios
donde están ubicados los datos en el catálogo de SGBDD.
Entonces el cliente puede planear la forma de transmitir los resultados
de las subconsultas a otros sitios para un procesamiento adicional
o para producir el resultado. Para lograr esto se requiere software
más complejo. |
| |
| TÉCNICAS
DE FRAGMENTACIÓN, REPLICACIÓN Y REPARTO DE LOS DATOS |
| |
Éstas
técnicas se utilizan para dividir la base de datos en unidades
lógicas, llamadas fragmentos, cuyo almacenamiento puede asignarse
a los diversos sitios. Con la replicación de datos es posible
almacenar ciertos datos en más de un sitio. Se utilizan éstos
métodos durante el proceso de diseño de la base de
datos distribuida. Toda la información concerniente a estos
temas se almacena en un catálogo global del sistema al
que tiene acceso el software cliente cuando lo solicita. |
| |
| Fragmentación
de los datos |
| |
Antes
de decidir cómo distribuir los datos, debemos determinar
las unidades lógicas de la base de datos que se van a distribuir.
Las unidades lógicas más simples son las relaciones
mismas, es decir, cada relación completa se almacenará
en un sitio específico. En muchos casos, es posible dividir
una relación en unidades lógicas más pequeñas
para su distribución. |
| |
Fragmentación
horizontal. Un
fragmento horizontal de una relación es un subconjunto de
las tuplas de esa relación, y se especifican mediante una
condición sobre uno o más atributos de la relación.
La fragmentación horizontal divide una relación "horizontalmente"
agrupando filas para crear subconjuntos de tuplas, donde cada subconjunto
tiene un cierto significado lógico. Estos fragmentos pueden
asignarse a diferentes sitios en un sistema distribuido. |
| |
Fragmentación
vertical. Un
fragmento vertical contiene sólo ciertos atributos de la
relación. Es importante recalcar que es necesario incluir
en toda fragmentación vertical el atributo de clave primaria
para que sea posible reconstruir la relación completa a partir
de los fragmentos. La fragmentación vertical divide una relación
"verticalmente" por columnas. |
| |
Se
denomina fragmentación horizontal completa a un conjunto de fragmentos
horizontales cuyas n condiciones incluyen todas las tuplas de la
relación. Este tipo de fragmentación se califica como
disjunta cuando ninguna tupla de R satisface (Ci AND Cj), para cualquier
i ( j. Para reconstruir la relación, se necesita aplicar
la operación UNIÓN a los fragmentos. |
| |
Se
denomina fragmentación vertical completa a un conjunto de fragmentos
verticales cuyas listas de proyección incluyen todos los
atributos de la relación, pero sólo comparten el atributo
de clave primaria. Para reconstruir la relación, se aplica
la operación de UNIÓN EXTERNA a los fragmentos. |
| |
Fragmentación
mixta. Podemos
entremezclar los dos tipos de fragmentación, para
obtener una fragmentación mixta. En algunos casos la relación
original se podría reconstruir aplicando operaciones de UNIÓN
y UNIÓN EXTERNA en el orden apropiado. |
| |
Un
esquema de fragmentación de una base de datos es una definición
de un conjunto de fragmentos que incluye todos los atributos y tuplas
de la base de datos y satisface la condición de que la base
de datos completa se puede reconstruir a partir de los fragmentos
mediante alguna secuencia de operaciones UNIÓN EXTERNA y
UNIÓN. A veces es útil que todos los fragmentos sean
disjuntos, excepto la repetición de claves primarias entre
fragmentos verticales o mixtos. |
| |
Un
esquema de reparto describe al reparto de fragmentos de la
base de datos
a través de los nodos y especifica en qué sitios
se almacena cada fragmento. |
| |
| Replicación
y reparto de los datos |
| |
La
replicación
es útil para mejorar la disponibilidad de los datos, pero
hay que ser equilibrado en la replicación, porque reduce
drásticamente la rapidez de las operaciones de actualización,
pues una sola actualización lógica se deberá
efectuar en todos los sitios donde esté replicado para
mantener la consistencia. |
| |
Cuando
la base de datos está repetida entera en todos los sitios,
se denomina replicación completa. Por el contrario, cuando
cada fragmento se almacena exactamente en un sitio, se denomina
reparto no redundante. Entre los dos extremos tenemos una amplia
gama de replicación parcial, es decir algunos fragmentos
de la base de datos están replicados y otros no. Un esquema
de replicación es una descripción de la replicación
de los fragmentos a través de los nodos del sistema. |
| |
Cada
fragmento debe asignarse a uno o más sitios de la base de
datos, este proceso se denomina reparto de los datos. La elección
de sitios y el grado de replicación dependen de los objetivos
de rendimiento y disponibilidad que tenga el sistema y de los tipos
y frecuencias de transacciones introducidas en cada sitio. Encontrar
una solución óptima, o siquiera buena, para el reparto
de datos distribuidos es un problema de optimización muy
complejo. |
| |
| TIPOS
DE SISTEMAS DE BASES DE DATOS DISTRIBUIDAS |
| |
Un
factor a tener en cuenta es el grado de homogeneidad del software
de SGBDD.
Si todos los servidores utilizan software idéntico y todos
los clientes utilizan software idéntico, se dice que es homogéneo,
de lo contrario se lo caracteriza como heterogéneo, en cual
caso se necesitará un lenguaje de sistema canónico
y traductores del lenguaje en el cliente a fin de traducir las subconsultas
del lenguaje canónico al lenguaje de cada servidor. |
| |
Se
dice que un SGBDD tiene autonomía local si se permite a las transacciones
locales acceso directo a un servidor, se dirá que no tiene
autonomía local si todo acceso debe hacerse a través
de un cliente. |
| |
Cuando
hablamos de un SGBDD federado, cada servidor es un sistema
centralizado
independiente y autónomo que tiene sus propios usuarios locales,
transacciones locales y DBA, y por ende, posee alto grado de autonomía
local. Cada servidor puede autorizar el acceso a porciones específicas
de su base de datos definiendo un esquema de exportación.
De esa manera, se permite a usuarios externos o globales tener acceso
a información almacenada en varios de estas bases de datos
autónomas. |
| |
Otro
aspecto es el grado de integración de los esquemas o grado
de transparencia de la distribución, que ya fue explicado
en el tema anterior. |
| |
| OPTIMIZACIÓN
DE CONSULTAS EN BASES DE DATOS DISTRIBUIDAS |
| |
| Costos
de la transferencia de datos en el procesamiento de consultas distribuidas |
| |
Los
factores adicionales que complican el procesamiento de consultas
en un SGBDD son varios. Uno de ellos es el costo de transferir
datos
por la red. Por ello, los algoritmos de optimización de consultas
de estos sistemas consideran como objetivo reducir la cantidad de
transferencias de datos al elegir estrategias de ejecución
para una consulta. |
| |
Es
por eso que al elegir un método para resolver una consulta,
si se tiene como objetivo reducir la cantidad de transferencia
por
medio de la red, ha de elegirse la estrategia que menos bytes
deba transferir. |
| |
Pero
existe una manera más compleja, que a veces funciona mejor,
que utiliza una estrategia llamada semirreunión. A continuación
estudiaremos esta operación y analizaremos la ejecución
distribuida con semirreuniones. |
| |
| Procesamiento
de consultas distribuidas por semirreunión |
| |
Esta
idea se basa en reducir el número de tuplas de una relación
antes de transferirla o otro sitio. Intuitivamente, la idea es enviar
la columna de reunión de una relación R al sitio donde
se encuentra la otra relación S para reunirlas allí. |
| |
Después
de ello, los atributos de reunión, junto con los atributos
requeridos en el resultado, se extraen por proyección y se
devuelven al sitio original donde se reúnen con R. Así
pues, sólo se transfiere la columna de reunión de
R en una dirección, y un subconjunto de S que no contenga
tuplas que no intervengan en el resultado se transfiere en la otra
dirección. En el caso en que solo una pequeña fracción
de las tuplas de S participan en la reunión, esto puede ser
una solución bastante eficiente para minimizar la transferencia
de datos. |
| |
La
operación
de semirreunión se inventó para formalizar esta estrategia.
Una operación de semirreunión R |X A=B S, donde A
y B son atributos de dominio compatible de R y S, respectivamente,
produce el mismo resultado que la expresión del álgebra
relacional ( <R> (R |X| A=B S). En un entorno distribuido
en el que R y S residen en diferentes sitios, la semirreunión
casi siempre se implementa transfiriendo primero F = ( <B>
(S) al sitio donde R reside y reuniendo después F y R, lo
que corresponde a la estrategia que acabamos de ver. Cabe señalar
que la estrategia de semirreunión no es conmutativa, es
decir: R |X S ( S |X R. |
| |
| Descomposición
de consultas y de actualizaciones |
| |
En
un SGBDD sin transparencia de distribución, el usuario expresa
su consulta directamente en términos de fragmentos específicos
y especificar en que sitios se encuentran los datos que desea reunir.
El usuario deberá mantener también la consistencia
de los elementos de información replicados cuando actualice
un SGBDD sin transparencia de replicación. |
| |
Por
otro lado, en caso de que se ofrezca transparencia de distribución,
de fragmentación y de replicación completa se permitirá
al usuario especificar una consulta o solicitud de actualización
igual que si el sistema fuese centralizado. |
| |
En
el caso de las consultas, un módulo de descomposición
de consultas deberá dividir o descomponer una consulta en
subconsultas que se puedan ejecutar en los sitios individuales.
Por añadidura, deberá generarse una estrategia para
combinar los resultados de las subconsultas y formar el resultado
de la consulta completa. Si hay elementos replicados, deberá
escoger una réplica específica a la que se hará
referencia durante la ejecución. |
| |
Para
esto, el SGBDD consulta la información de fragmentación,
replicación y distribución almacenada en su catálogo.
Para la descomposición de consultas, el sistema puede determinar
cuáles fragmentos contienen las tuplas requeridas comparando
la condición de consulta y las condiciones de guardia de
los fragmentos. Luego el optimizador de consultas estimaría
los costos de las estrategias probables y escogería la que
tuviera la estimación más baja. |
| |
| CONTROL
DE CONCURRENCIA Y RECUPERACIÓN EN SGBDD |
| |
|
Como
hemos notado, algunos problemas que surgen en sistema de bases
de datos distribuido son:
- Mantenimiento
de consistencia cuando se manejan múltiples copias de
elementos de información
- Mantener
la operación si falla un sitio individual y actualizar
la información del sitio caído cuando éste
se recupere.
- Capacidad
para manejar fallos de enlaces de comunicaciones o cuando hay
partición en la red.
- Utilización
del protocolo de confirmación de dos fases para resolver
el problema cuando falla un sitio durante el proceso de confirmación
de múltiples sitios.
- Extensión
de las técnicas de manejo de bloqueos mortales entre
varios sitios.
|
| Las
técnicas de control de concurrencia y de recuperación
distribuidos deben resolver éstos y otros problemas. |
| |
| Control
de concurrencia distribuido basado en una copia distinguida de un
elemento de información. |
| |
La
idea es designar una copia determinada de cada elemento de
información
como copia distinguida, entonces todas las solicitudes de bloqueo
y desbloqueo se envían al sitio que contiene esa copia. Hay
varios métodos diferentes que se basan en esta idea, pero
difieren en la forma en que escogen las copias distinguidas. |
| |
Técnica
de sitio primario. Se designa un solo sitio primario como sitio
coordinador para todos los elementos de la base de datos. Todos
los candados y todas las solicitudes de bloqueo y desbloqueo se
envía a ese sitio. La ventaja de este enfoque es que es una
simple extensión del enfoque centralizado y por tanto no
es demasiado complejo. Las desventajas son que posiblemente se sobrecargue
el sitio primario y se origine un cuello de botella allí,
y además un fallo en este sitio paralizaría el
sistema completo. Esto limita la fiabilidad y la disponibilidad
del sistema. |
| |
Sitio
primario con sitio de respaldo. Este enfoque busca solucionar
el
fallo del sitio primario, y para ello se designa un segundo sitio
como sitio de respaldo. El problema que esto trae aparejado
es que
el proceso de adquisición de candados se hace más
lento, porque todas las solicitudes de candados y la concesión
de los mismos se deben asentar tanto en el sitio primario como en
el de respaldo antes de enviar una respuesta a la transacción
solicitante. Además, ésta técnica no resuelve
el problema de sobrecarga del sitio primario con todas las solicitudes. |
| |
Técnica
de copia primaria. Este método intenta distribuir la carga
de coordinación de los candados entre varios sitios, manteniendo
copias distinguidas almacenadas en diferentes sitios. El fallo de
un sitio no afecta a todas las transacciones, sino solamente a algunas.
Este método también puede usar sitios de respaldo
para elevar la fiabilidad y la disponibilidad.
Siempre que un sitio coordinador falle en cualquiera de las técnicas
anteriores, los sitios que siguen activos deberán elegir
un nuevo coordinador. En el caso de la técnica de sitio primario,
habrá que abortar y reiniciar todas las transacciones, lo
que se transforma en algo tedioso. En los métodos que usan
sitio de respaldo, el procesamiento de transacciones se suspende
mientras el sitio de respaldo se designa como nuevo sitio primario
y se escoge un nuevo sitio de respaldo enviando toda la información
allí. El algoritmo para que un sitio escoja un sitio de
respaldo en caso de que no lo halla es bastante complejo. |
| |
| Control
de concurrencia distribuido basado en votación |
| |
En
el método de votación cada solicitud de bloqueo se envía
a todos los sitios que incluyan una copia del elemento en cuestión.
Si la mayoría de las copias otorgan un candado a la transacción
que lo solicita, ésta poseerá el candado e informará
a todas las copias que ha sido concedido. En caso contrario, se
espera un cierto período de tiempo y en caso de que no
se conceda el candado, se cancela la solicitud y se informa a
todos
los sitios. |
| |
La
votación
tiene un tráfico más alto de mensajes entre sitios
que los métodos de copia distinguida. Si el algoritmo tiene
en cuenta posibles fallos de sitios durante el proceso de votación,
se vuelve extremadamente complejo. |
| |
| Recuperación
distribuida |
| |
El
proceso de recuperación en las bases de datos distribuidas
es bastante complicado. Por ejemplo, supongamos que el sitio X envía
un mensaje al sitio Y y espera una respuesta de Y, pero no la recibe.
Hay varias causas posibles:* El mensaje no llegó a Y debido
a un fallo en la comunicación.* El sitio Y está inactivo
y no pudo responder.* El sitio Y está activo y envió
una respuesta, pero ésta no llegó.Es difícil
determinar que sucedió realmente. Otro problema con la recuperación
distribuida es la confirmación distribuida. Cuando una transacción
está actualizando datos en varios sitios, no puede confirmarse
hasta estar segura de que todos los sitios han recibido los datos.
A menudo se utiliza el protocolo de confirmación de dos fases
para garantizar la correción de la confirmación
distriuida. |
| |
| CONCLUSIÓN |
| |
| Ventajas
del procesamiento distribuido |
| |
Mejor
rendimiento si los datos pueden estár cerca del punto de
su utilización, de forma que el tiempo de comunicación
puede ser más corto. Varias computadoras en forma simultánea
entregan más volumen de procesamiento que una sola.
Más confiabilidad si gracias a la replicación de
datos, cuando falla un nodo pueden obtenerse datos de otro nodo.
Los usuarios
no dependen de la disponibilidad de una sola fuente para sus
datos. |
| |
Variación
de tamaño mas sencillo. Se pueden agregar computadoras adicionales
a la red conforme aumentan el número de usuarios y la carga
de procesamiento. Es más fácil y más barato
que actualizar una sola computadora única y centralizada. |
| |
Adecuación más sencilla a las estructuras de organización
de los usuarios. |
| |
| Desventajas
del procesamiento distribuido |
| |
Menor
rendimiento si la carga de trabajo necesita un gran número
de actualizaciones concurrentes sobre duplicados que están
demasiado distribuidos. |
| |
Menor
confiabilidad si son de bajo poder las computadoras de procesamiento
y la red de datos, ya que pueden ser sensibles a muchas fallas.
Si está mal usada la replicación de datos y es mala
la distribución el sistema posee baja confiabilidad. |
| |
Altos
gastos de construcción y mantenimiento. Existen más
componentes de hardware, hay más cantidad de cosas para aprender
y más interfaces susceptibles de fallar. El control de concurrencia
y recuperación puede ser algo muy difícil de implementar
para los programadores y personal de operación poco experimentados. |
| |
Difícil
de controlar. Las computadoras del proceso, que residen en diferentes
lugares, no reciben a veces control, o los procedimientos operativos
son demasiado suaves y efectuados por personas que tienen escasa
apreciación o compresión de su importancia. |
| |
| Objetivos
del procesamiento distribuido* |
| |
Transparencia
de localización. Las transacciones necesitan ser independientes
de la localización de un elemento de datos en particular.
Esto se logra mediante algoritmos de localización que utiliza
el SGBDD utilizando el catálogo dónde se especifica
donde encontrar los datos. El sistema decidirá cuál
es la mejor estrategia a seguir para abaratar costos de comunicación. |
| |
Transparencia
de duplicación. La transacción debe actuar como si
todos los datos estuvieran almacenados una vez en un sólo
nodo. Para esto, los administradores de transacciones deben traducir
las solicitudes de procesamiento en acciones de elección
de nodos a utilizar, según cuál sea el de mejor
rendimiento. |
| |
Transparencia
de concurrencia. Los resultados de las transacciones que se llevan
a cabo al mismo tiempo no deben alterarse. Para esto se utiliza
el bloque distribuido en dos fases. |
| |
Transparencia
de fallas. Las transacciones serán procesadas de un modo
correcto a pesar de fallas en los nodos. Las transacciones deberán
ser atómicas, se procesan todas o ninguna de ellas. Como
notamos, las fallas pueden ser muy variadas, así que este
tipo de transparencia es algo muy difícil de lograr. |
| |
| Tecnologías
de Acceso a Datos |
| |
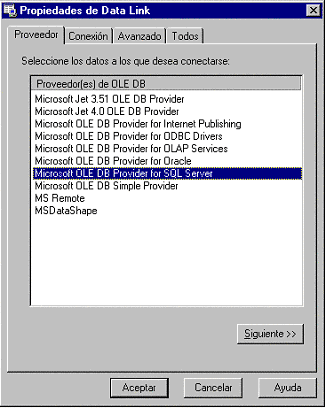
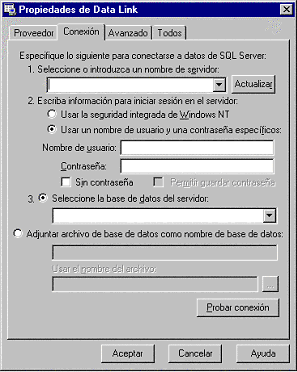
| Conectarse a un SQL Server |
| |
| Comenzando
con ADO - ActiveX Data Objects |
| |
| Definición |
| |
ADO
en ActiveX Data Objets es un modelo de objetos de acceso a
datos
que se apoya sobre OLEDB. Permite dirigir los datos que vienen
de bases de datos relacionales (SQL Server, Oracle…),
o de otras fuentes de datos no relacionales como ficheros de
texto, fuentes
de datos que no son de Microsoft, etc. Es un medio para acceder
uniformemente a todos los tipos de datos. En cierta manera
podemos
decir que ODBC permite acceder a bases de datos relacionales,
mientras que OLEDB permite el acceso a todos los tipos de datos,
sean relacionales
o no. |
| |
Este
modelo de objetos se ha introducido como modelo de acceso de
datos
para IIS. Sus principales características son las siguientes: |
| |
Mínimo
tráfico en
la red Thread Safe (soportando accesos concurrentes o multithread)
Número mínimo de capas entre las aplicaciones y
los datos. |
| |
Facilidad
de utilización: modelo
de objetos automatizado Tiene en cuenta los conocimientos
adquiridos por los desarrolladores sobre la otras tecnologías
como DAO o RDO |
| |
Arquitectura
tecnológica
|
| |
OLEDB
es una tecnología que tiene como objetivo resolver ciertas
restricciones de ODBC. Esta tecnología autoriza el acceso
a todo tipo de datos, permitiendo administrar el aspecto de tener
distribuidas las fuentes de datos, y tiene en cuenta las restricciones
de la web. Esta tecnología tiene como objetivo reemplazar
a la tecnología ODBC. ADO es el modelo de objetos que permite
simplificar el acceso a esta tecnología. |
| |
Un
proveedor OLEDB implementa las interfaces OLEDB. Permite a
un usuario OLEDB
alcanzar todo tipo de fuentes de datos de una manera uniforme
a través de este juego de interfaces documentado. En cierto
sentido, un proveedor OLEDB es similar a un driver ODBC que proporciona
un mecanismo uniforme de acceso a los datos relacionales. Los proveedores
OLEDB no sólo proporcionan un mecanismo uniforme de acceso
a los datos relacionales, si no que también a datos no relacionales.
Además, los proveedores OLEDB se construyen sobre la base
del modelo COM (Component Objet Model) mientras que los drivers
ODBC están basados en una especificación de APIs
de C. |
| |
| El
modelo de objetos ADO |
| |
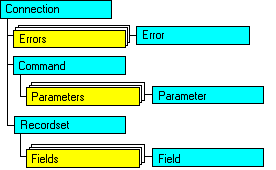
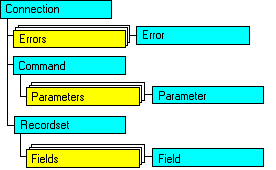
El esquema
siguiente muestra los objetos y las relaciones existentes entre
los objetos y el modelo.
|
| |
| Objetos
y Colecciones del modelo de objetos ADO |
| |
Los
objetos Connection, Recordset y Command son los objetos más
significativos de este modelo. Clásicamente, una aplicación
las utiliza como:
| Objeto
o Colección |
Utilización |
| Objeto
Connection |
Permite
establecer las conexiones entre el cliente y el origen de
datos |
| Objeto
Command |
Permite
realizar los comandos, como las consultas SQL o las actualizaciones
de una base de datos. |
| Objeto
Recordset |
Permite
ver y manipular los resultados de una consulta |
| Colección
Parameters |
Es
utilizada cuando la consulta del objeto Command necesita
los
parámetros. |
| Colección
Errors |
La
colección Errors y el objeto Error se acceden a través
del objeto Connection, a no ser que se produzca un error de
proveedor . El objeto Error es diferente del objeto Err de
VB, en la medida en que no contiene los errores generados
y definidos por el proveedor, por lo tanto, permite obtener
información precisa sobre la causa del error. |
| Colección
Fields |
La
colección Fields y el objeto Field se utilizan a través
del objeto Recordset, una vez que éste contiene
los datos. |
|
| |
| Descripción
de los objetos y colecciones |
| |
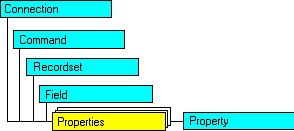
La
colección
Properties proporciona la información sobre las características
de los diferentes objetos Connection, Command, Recordset y Field.
Cada objeto de Property es accesible a través de la colección
Properties de cada uno de estos objetos.
|
| |
| Colección
Properties |
| |
Aunque
ADO es un modelo del tipo jerárquico, los objetos de ADO,
excepto Error, Field y Property pueden crearse de forma autónoma,
es decir, sin hacer referencia al objeto relacionado. Esto es diferente
de los objetos DAO y RDO, que requieren en la mayoría de
los casos la creación del objeto Parent (por ejemplo,
un objeto DAO.Connection necesita un objeto DAO.Workspace para
poder
crearse). |
| |
ADO
es un modelo de objetos que permite una gran flexibilidad al
programador.
Por consiguiente, hay distintas posibilidades para lograr la
misma tarea. Por ejemplo, para ejecutar una consulta, es posible
usar
el método Execute del objeto Command o bien el del objeto
Connection. |
| |
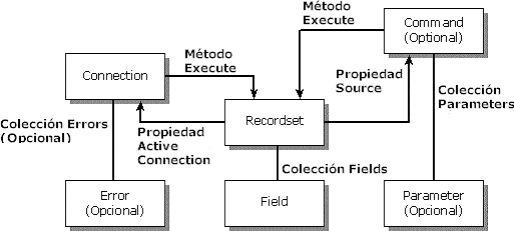
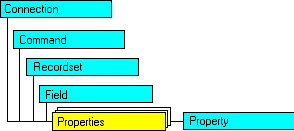
En resumen,
este es un diagrama que muestra las relaciones entre los diferentes
objetos que constituyen ADO:
|
| |
| Ejemplos
de ADO |
| |
Abrir
y cerrar una conexión con una base de datos SQL Server
usando el proveedor por defecto que es el proveedor de OLEDB
para ODBC |
| |
Sub
ConnectionExample1()
Dim cn As ADODB.Connection
Set cn = New ADODB.Connection |
| |
' Abrir
la conexión, especificando el nombre del origen de datos,
' id de usuario, y contraseña.
cn.Open "DSNPubs", "sa", "" |
| |
' Si
la conexión está abierta, lo muestra.
If cn.State = adStateOpen Then
| |
Debug.Print
"Conexión abierta." |
End If
|
| |
' Cerrar
la conexión.
cn.Close End Sub |
| |
| Abrir
y cerrar una conexión con una base de datos SQL Server usando
el proveedor OLEDB para SQL Server que es el proveedor recomendado |
| |
Private
Sub ConnectionExemple2()
Dim cn As New ADODB.Connection |
| |
cn.Provider
= "SQLOLEDB"
cn.Open "Data Source=MySQLServerName;Initial Catalog=pubs;",
"sa", "" |
| |
' Si
la conexión está abierta, lo muestra.
If cn.State = adStateOpen Then
| |
Debug.Print
"Conexión abierta." |
End If
|
| |
' Cerrar
la conexión.
cn.Close
Set cn = Nothing |
| |
| End
Sub |
| |
| Abrir
y cerrar un Recordset |
| |
| Sub
RecordsetExample() Dim rs As |
| |
New
ADODB.Recordset ' Abrir el recordset, especificando la
sentencia SQL ' y la cadena
de conexión. rs.Open "Select * fromtitles","DSN=pubs;UID=sa"
|
| |
' Bucle
a través del recordset e impresión del primer campo.
Do While Not rs.EOF
| |
Debug.Print
rs(0)
rs.MoveNext |
Loop |
| |
' Cerrar
el recordset.
rs.Close |
| |
| End
Sub |
| |
| Usar
el método Execute del objeto Command para ejecutar una consulta
de tipo texto |
| |
Sub
CommandExample()
Dim cmd As New ADODB.Command
Dim rs As New ADODB.Recordset |
| |
' Establecer
el comando conexión usando una cadena de conexión.
cmd.ActiveConnection = "DSN=pubs;UID=sa" |
| |
' Establecer
el comando texto, y especificar que es ' una sentencia SQL.
cmd.CommandText = "Select * from titles"
cmd.CommandType = adCmdText |
| |
' Crear
un recordset.
Set rs = cmd.Execute() |
| |
' Bucle
a través del recordset e impresión del primer campo.
Do While Not rs.EOF
| |
Debug.Print
rs(0)
rs.MoveNext |
Loop
|
| |
' Cerrar
el recordset.
rs.Close |
| |
| End
Sub |
| |
| Usar
el método Execute del objeto Command para ejecutar un procedimiento
de almacenado |
| |
Sub
ParameterExample()
Dim cmd As New ADODB.Command
Dim rs As New ADODB.Recordset
Dim prm As ADODB.Parameter |
| |
' Establecer
el comando conexión usando una cadena de conexión.
cmd.ActiveConnection = "DSN=pubs;uid=sa" |
| |
' Establecer
el comando texto, y especificar que es
' una sentencia SQL.
cmd.CommandText = "byroyalty"
cmd.CommandType = adCmdStoredProc |
| |
' Establecer
un nuevo parámetro para el procedimiento guardado.
Set prm = cmd.CreateParameter("Royalty", adInteger, adParamInput,
, 50)
cmd.Parameters.Append prm |
| |
' Crear
un recordset.
Set rs = cmd.Execute |
| |
' Bucle
a través del recordset e impresión del primer campo.
Do While Not rs.EOF
| |
Debug.Print
rs(0)
rs.MoveNext |
Loop |
| |
' Cerrar
el recordset.
rs.Close |
| |
| End
Sub |
| |
| Almacenar
los resultados de una consulta Access en un fichero Excel |
| |
Private
Sub Command1_Click()
Dim cn As ADODB.Connection |
| |
Set
cn = New ADODB.Connection
cn.Open "Provider=Microsoft.Jet.OLEDB.4.0;Data Source= c:\bd1.mdb"
cn.Execute "Select * into [Excel8.0];Database=c:\Test1.xls;Hdr=Yes].[Sheet3]
From Clients" |
| |
| cn.Close |
| |
| Set
cn = Nothing |
| |
| End
Sub |
| |
| ' Explorar
la colección Errors. |
| |
Sub
ErrorExample()
Dim cn As ADODB.Connection
Set cn = New ADODB.Connection
On Error GoTo AdoError |
| |
' Abrir
la conexión usando un DSN que no existe.
cn.Open "MissingDSN", "sa", "" |
| |
| Exit
Sub |
| |
AdoError:
| |
Dim
Errs As ADODB.Errors
Dim errLoop As Error
Dim strError As String |
|
| |
' Bucle
hasta el objeto Error en la
' colección Errors y muestra las propiedades. |
| |
Set
Errs = cn.Errors
For Each errLoop In Errs
| |
Debug.Print
errLoop.SQLState
Debug.Print errLoop.NativeError
Debug.Print errLoop.Description |
Next
End Sub |
| |
| Enumerar
los campos (nombre, tipo y valor) de un recordset |
| |
| Sub
FieldExample() |
| |
Dim
rs As ADODB.Recordset
Dim fld As ADODB.Field |
| |
Set
rs =
New ADODB.Recordset ' Abrir el recordset, especificando la
sentencia SQL ' y la cadena
de conexión. rs.Open "Select * fromauthors","DSN=pubs;UID=sa"
|
| |
| Debug.Print
"Fields in Authors Table:" & vbCr |
| |
' Bucle
hasta el objeto Field en la
' Colección Fields de la tabla y muestra las propiedades.
For Each fld In rs.Fields
Debug.Print "Name: " & fld.Name & vbCr & _
"Type: " & fld.Type & vbCr & _
"Value: " & fld.Value
Next fld |
| |
' Cierre
del recordset.
rs.Close |
| |
| End
Sub |
| |
| Mostrar
los valores de ciertas propiedades de una conexión (el curso
de la colección de Properties) |
| |
Sub
PropertyExample()
Dim cn As New ADODB.Connection
Dim cmd As New ADODB.Command
Dim rs As New ADODB.Recordset |
| |
' Abrir
la conexión, especificando el nombre del origen de datos,
' id del usuario, u contraseña.
cn.Open "pubs", "sa" |
| |
' Establecer
el comando conexión usando una cadena de conexión.
Set cmd.ActiveConnection = cn
' Establecer el comando texto, especificando que es una sentencia
SQL.
cmd.CommandText = "Select * from titles"
cmd.CommandType = adCmdText |
| |
' Crear
el recordset.
Set rs = cmd.Execute() |
| |
' Muestra
la propiedad ConnectionTimeout de la conexión.
Debug.Print cn.Properties("Connect Timeout") |
| |
' Muestra
la propiedad CommandTimeout del comando.
Debug.Print cmd.Properties("Command Time out") |
| |
' Muestra
la propiedad Updatability del recordset.
Debug.Print rs.Properties("Updatability") |
| |
' Cierra
el recordset.
rs.Close |
| |
| End
Sub |
| |
| Las
cadenas de conexión |
| |
Si
necesita escribir una cadena de conexión, existe una manera de generarla
con el asistente de creación de una conexión de
datos. |
| |
|
Se
puede usar esta herramienta de creación de conexiones de
datos en VB:
- Utilize
el menú Ver y seleccione Ventana de la vista Datos
- Cree
un Entorno de datos haciendo clic en el botón derecho
en la ventana de datos.
-
En
la ventana Entorno de datos, hacer clic en el botón derecho
sobre Connection1 para ver las características de la
conexión (el proveedor, DSN, las propiedades específicas).
- Probar
la conexión antes de hacer clic en el botón de
Aceptar
-
Entrar
en la ventana de propiedades y seleccionar el objeto Connection1:
La propiedad DataSource contiene la cadena de conexión
necesaria.
|
| |
| Modelo
de objetos de ADO |
| |
| Objetos
de datos ActiveX |
| |
Los
Objetos de datos ActiveX® (ActiveX® Data Object, ADO) constituyen
una interfaz de Microsoft, estratégica y de alto nivel, para
toda clase de datos. ADO constituye un método de acceso a
datos coherente y de alto rendimiento, tanto cuando se crea una
base de datos cliente de usuario, como si se crea un objeto de trabajo
de capas intermedias con una aplicación, herramienta, lenguaje
o, incluso, con un explorador de Internet. ADO es la única
interfaz de datos necesaria para programar soluciones cliente/servidor
de 1 a n capas y soluciones basadas en datos Web. |
| |
ADO
está diseñada como una interfaz de nivel de aplicación,
fácil de usar, para el modelo más reciente y potente
de acceso a datos de Microsoft, OLE DB. OLE DB proporciona acceso
de alto rendimiento a cualquier origen de datos, como las bases
de datos relacionales y no relacionales, los sistemas de correo
electrónico y archivo, texto y gráficos, los objetos
de trabajo personalizados, etc. ADO se implementa con un mínino
de tráfico de red en escenarios Internet clave y con un mínino
de capas entre los datos de origen y los resultados proporcionando
una interfaz ligera y de altas prestaciones. |
| |
ADO
es fácil de usar porque se activa mediante un método
conocido: la interfaz OLE, disponible prácticamente en todas
las herramientas y lenguajes existentes actualmente en el mercado.
Y, puesto que los ADO han sido diseñados para combinar las
mejores funciones de RDO y DAO, y eventualmente para sustituirlos,
utiliza convenciones similares con semántica simplificada
que facilitan el aprendizaje a los programadores. |
| |
Modelo
de objetos de ADO
|
| |
Cada
uno de los objetos Connections,Command,Recordset y Field También
tiene una colección Properties.
|
| |
| Objetos
ADO |
| |
| Command,
objeto (ADO) Descripción |
| |
| Un objeto
Command es la definición de un comando específico
que se piensa ejecutar contra un origen de datos. |
| |
|
Utilice
un objeto Command para consultar una base de datos y obtener registros
en un objeto Recordset para ejecutar una operación de manejo
masivo de datos o para manipular la estructura de una base de
datos. Dependiendo de la funcionalidad del proveedor, algunas
colecciones, métodos o propiedades de Command pueden generar
un error cuando se les haga referencia. Con las colecciones, métodos
y propiedades de un objeto Command, puede hacer lo siguiente:
- Definir
el texto ejecutable del comando (por ejemplo, una instrucción
SQL) con la propiedad CommandText.
-
Definir
consultas parametrizadas o argumentos de procedimientos
almacenados
con los objetos Parameter y la colección Parameters.
- Ejecutar
un comando y obtener un objeto Recordset si resulta apropiado
con el método Execute.
- Especificar
el tipo de comando con la propiedad CommandType antes de la
ejecución para optimizar el rendimiento.
-
Controlar
con la propiedad Prepared, si el proveedor guarda una versión
preparada (o compilada) del comando antes de la ejecución.
-
Establecer
el número de segundos que un proveedor esperará que
el comando se ejecute con la propiedad CommandTimeout.
- Asociar
una conexión abierta con un objeto Command estableciendo
su propiedad ActiveConnection.
- Establecer
la propiedad Name para identificar el objeto Command como un
método del objeto Connection asociado.
- Pasar
un objeto Command a la propiedad Source de un Recordset para
obtener los datos.
|
Nota:
Para ejecutar una consulta sin utilizar un objeto Command,
pase
una cadena de consulta al método Execute de un objeto Connection
o al método Open de un objeto Recordset. Sin embargo, se
requiere un objeto Command cuando quiera que el texto del comando
persista y volver a ejecutarlo, o utilizar parámetros
en la consulta. |
| |
Para
crear un objeto Command independientemente de un objeto Connection
previamente definido, establezca su propiedad ActiveConnection
a
una cadena de conexión válida. ADO sigue creando un
objeto Connection, pero no asigna dicho objeto a una variable de
objeto. Sin embargo, si va a asociar varios objetos Command con
la misma conexión, tiene que crear y abrir de forma explícita
un objeto Connection; esto asigna el objeto Connection a una variable
de objeto. Si no establece la propiedad ActiveConnection de los
objetos Command a esta variable de objeto, ADO crea un nuevo objeto
Connection por cada objeto Command, incluso si utiliza la misma
cadena de conexión. Para ejecutar un Command, sólo
invóquelo utilizando su propiedad Name en el objeto Connection
asociado. El objeto Command ha de tener su propiedad ActiveConnection
establecida al objeto Connection. Si el objeto Command tuviera parámetros,
pase los valores de los parámetros como argumentos del método. |
| |
| Propiedades |
| |
| Propiedad
ActiveConnection (ADO), Propiedad CommandTect (ADO), Propiedad |
| |
| CommandTimeout
(ADO), Propiedad CommandType (ADO), Propiedad Prepared (ADO), Propiedad
State (ADO). |
| |
| Métodos |
| |
| Método
Cancel (ADO), Método CreateParameter (ADO), Método
Execute (ADO Command), Método Execute (ADO Connection). |
| |
| Colecciones |
| |
| Colección
Properties, Colección Parameters. |
| |
| Connection,
objeto (ADO) Descripción |
| |
|
Un
objeto Connection representa una conexión abierta con un
origen de datos.
Un objeto Connection representa una sesión única
con un origen de datos. En el caso de un sistema de base de datos
cliente/servidor, puede ser equivalente a una conexión
de red actual con el servidor. Dependiendo de la funcionalidad
que acepte el proveedor, algunas colecciones, métodos o
propiedades de un objeto Connection puede que no estén
disponibles. Mediante las colecciones, métodos y propiedades
de un objeto Connection puede hacer lo siguiente:
- Configurar
la conexión antes de abrirla con las propiedades ConnectionString,
ConnectionTimeout y Mode.
- Establecer
la propiedad CursorLocation para invocar al Client Cursor Provider,
que acepta actualizaciones por lotes.
- Establecer
la base de datos predeterminada para la conexión con
la propiedad DefaultDatabase.
- Establecer
el nivel de aislamiento de las transacciones abiertas en la
conexión con la propiedad IsolationLevel.
- Especificar
un proveedor de OLE DB con la propiedad Provider.
- Establecer,
y después romper, la conexión física con
el origen de datos con los métodos Open y Close.
- Ejecutar
un comando en la conexión con el método Execute
y configurar la ejecución con la propiedad CommandTimeout.
-
Administrar
transacciones en la conexión abierta, incluyendo transacciones
anidadas si el proveedor las acepta, con los métodos
BeginTrans, CommitTrans y Rolí-backjrans y la propiedad
Attributes.
- Examinar
los errores devueltos por el origen de datos con la colección
Errors.
- Leer
la versión de la implementación de ADO en uso
con la propiedad Version.
-
Obtener información del esquema de la base de datos con
el método OpenSchema.
|
Nota:
Para ejecutar una consulta sin utilizar un objeto Command,
pase
una cadena de consulta al método Execute de un objeto Connection.
Sin embargo, se requiere un objeto Command cuando se quiere que
el texto del comando persista y se vuelva a ejecutar, o utilice
parámetros en la consulta. |
| |
| Puede
crear objetos Connection de forma independiente de cualquier objeto
previamente definido. |
| |
| Nota:
Se pueden ejecutar comandos o procedimientos almacenados como si
fuesen métodos nativos del objeto Connection. |
| |
Para
ejecutar un comando, dé un nombre al comando mediante la
propiedad Name del objeto Command. Establezca la propiedad ActiveConecction
del objeto Command como la conexión. Después emita
una instrucción donde el nombre del comando se utilice como
si fuese un método del objeto Connection, seguido de cualquier
parámetro, seguido de un objeto Recordset si se devuelve
alguna fila. Establezca las propiedades del Recordset para personalizar
el conjunto de registros resultante: |
| |
Para
ejecutar un procedimiento almacenado, emita una instrucción
donde se utilice el nombre del procedimiento almacenado como si
fuese un método del objeto Connection, seguido de sus parámetros.
ADO realizará una "mejor suposición" de
los tipos de parámetros |
| |
| Propiedades |
| |
| Propiedad
Attributes (ADO), Propiedad CommandTimeout (ADO), Propiedad ConnectionString
(ADO), Propiedad ConnectjonTimeout (ADO), Propiedad CursorLocation
(ADO), Propiedad DefaultIDatabase (ADO), Propiedad IsolationLevel
(ADO), Propiedad Mode (ADO), Propiedad Provider (ADO), Propiedad
State (ADO), Propiedad Version (ADO). Objetos ADO 1315 |
| |
| Métodos |
| |
| Métodos
BeginTrans, CommitTrans y RollbackTrans (ADO>, Método
Cancel (ADO), Método Close (ADO), Método Execute (Comando
ADO), Método Execute (Conexión ADO), Método
Open (Conexión ADO), Método Open (Conjunto de Registros
ADO), Método OpenSchema (ADO), Método Save (Conjunto
de Registros ADO). |
| |
| Colecciones |
| |
| Colección
Properties, Colección Errors. |
| |
| Error,
objeto (ADO) Descripción |
| |
| Un objeto
Error contiene los detalles sobre los errores de acceso a los datos
pertenecientes a una única operación relacionada con
el proveedor. |
| |
Cualquier
operación relacionada con objetos ADO puede generar uno o
varios errores del proveedor. Al ocurrir los errores, uno o varios
objetos Error se agregan a la colección Errors del objeto
Connection. Cuando otra operación ADO genera un error, se
borra la colección Errors y el nuevo conjunto de objetos
Error se agrega a la colección Errors. |
| |
Nota:
Cada objeto Error representa un error del proveedor concreto,
no
un error de ADO. Los errores de ADO pasan al mecanismo de control
de excepciones de ejecución. Por ejemplo, en Microsoft Visual
Basic, la ocurrencia de un error concreto de ADO desencadenará
un evento On Error y aparecerá en el objeto Err. Para obtener
la lista completa de los errores de ADO, vea el tema Códigos
de error ADO tema. |
| |
|
Puede
leer las propiedades de un objeto Error para obtener detalles
específicos sobre cada error, incluyendo los siguientes:
- La
propiedad Description, que contiene el texto del error.
- La
propiedad Number, que contiene el valor entero Long de la constante
del error.
-
La
propiedad Source, que identifica el objeto que ha provocado
el error. Esto es particularmente útil cuando tiene varios
objetos Error en la colección Errors después de
una petición a un origen de datos.
-
Las
propiedades SQLState y NativeError, que proporcionan información
desde orígenes de datos SQL.
|
Cuando
ocurre un error en el proveedor, se agrega a la colección
Errors del objeto Connection. ADO acepta la devolución de
varios errores por una misma operación ADO para permitir
tener acceso a la información de error específica
del proveedor. Para obtener esta rica información de error
en un controlador de errores, utilice las funciones de interceptación
de errores apropiadas de su lenguaje o entorno de trabajo y después
utilice bucles anidados para enumerar las propiedades de cada objeto
Error de la colección Errors. |
| |
| Microsoft
Visual Basic y VBScript. Si no hay un objeto Connection válido,
tendrá que obtener la información de error desde el
objeto Err. |
| |
Igual
que los proveedores, ADO borra el objeto OLE Error Info antes
de
hacer una llamada que pueda generar un nuevo error del proveedor.
Sin embargo, la colección Errors del objeto Connection sólo
se borra y se llena cuando el proveedor genera un nuevo error, o
cuando se invoca el método Clear. Algunas propiedades y métodos
devuelven advertencias que aparecen como objetos Error en la colección
Errors, pero no detienen la ejecución de los programas. Antes
de invocar los métodos Resync, UpdateBatch o CancelBatcb
de un objeto Recordset, el método Open de un objeto Connection,
o de establecer la propiedad Filter de un objjeto Recordset, invoque
el método Clear de la colección Errors para que pueda
leer la propiedad Count de la colección Errors y comprobar
las advertencias devueltas. |
| |
| Propiedades |
| |
| Propiedad
Description (ADO), Propiedad NaviteError (ADO), Propiedad Number
(ADO), Propiedad Source (ADO Error), Propiedad SQLState (ADO), Archivo
Help. |
| |
| Field,
objeto (ADO) |
| |
|
Un
objeto Field representa una columna de datos con un tipo de datos
comun.
Un objeto Recordset tiene una colección Fields que consiste
en varios objetos Field. Cada objeto Field se corresponde con
una columna del Recordset. La propiedad Value de los objetos Field
se utiliza para establecer u obtener los datos del registro actual.
Dependiendo de la funcionalidad ofrecida por el proveedor, algunas
colecciones, métodos o propiedades de un objeto Field puede
que no estén disponibles. Con las colecciones, métodos
y propiedades de un objeto Field, puede hacer lo siguiente:
- Obtener
el nombre de un campo con la propiedad Name.
- Ver
o modificar los datos del campo con la propiedad Value.
- Obtener
las características básicas de un campo con las
propiedades Type, Precision y NumericScale. · Obtener
el tamaño declarado de un campo con la propiedad DefinedSize.
- Obtener
el tamaño actual de los datos de un campo dado con la
propiedad ActualSize
- Determinar
qué tipos de funcionalidad se aceptan para un campo dado
con la propiedad Attributes y la colección Properties.
-
Manipular
los valores de los campos que contengan datos binarios
o de
gran tamaño con los métodos AppendChunk y GetChunk.
· Si el proveedor acepta actualizaciones por lotes, resolver
discrepancias en los valores de tos campos durante una actualización
por lotes con las propiedades OriginalValue y UnderlyingValue.
|
Todas
las propiedades de metadatos (Name, Type, DefinedSize, Precision
y NumericScale) están disponibles antes de abrir el Recordset
del objeto Field. Su establecimiento en tal momento es útil
en la generación dinámica de formularios.
Propiedades Propiedad ActualSize (ADO), Propiedad Attributes (ADO),
Propiedad DefinedSize (ADO), Propiedad Name (ADO), Propiedad NumericScale
(ADO), Propiedad OriginalValue (ADO), Propiedad Precision (ADO),
Propiedad Type (ADO), Propiedad UnderlyingValue (ADO), Propiedad
Value (ADO).
Métodos Método AppendChunk (ADO), Método
GetChunk (ADO).
Colecciones Colección Properties. |
| |
| Parameter,
objeto (ADO) |
| |
Un
objeto Parameter representa un parámetro o un argumento
asociado con un objeto Command basado en una consulta parametrizada
o en
un procedimiento almacenado. |
| |
|
Muchos
proveedores aceptan comandos parametrizados. Estos son comandos
en los que la acción deseada está definida una sola
vez, pero se utilizan variables (o parámetros) para alterar
algunos detalles del comando. Por ejemplo, una instrucción
SQL SELECT podría utilizar un parámetro para definir
los criterios de búsqueda de la cláusula WHERE,
y otro para definir el nombre de la columna de la cláusula
SORT BY. Los objetos Parameter representan parámetros asociados
con consultas parametrizadas, o los argumentos de entrada/salida
y los valores devueltos por los procedimientos almacenados. Dependiendo
de la funcionalidad del proveedor, algunas colecciones, métodos
o propiedades de un objeto Parameter puede que no estén
disponibles. Con las colecciones, métodos y propiedades
de un objeto Parameter, puede hacer lo siguiente:
- Establecer
u obtener el nombre de un parámetro con la propiedad
Name.
- Establecer
u obtener el valor de un parámetro con la propiedad Value.
-
Establecer
u obtener características de un parámetro
con las propiedades Attributes, Direction, Precision, NumericScale.
Size y Type.
- Pasar
datos binarios o de gran tamaño a un parámetro
con el método AppendChunk.
|
Si
conoce los nombres y las propiedades de los parámetros asociados
con el procedimiento almacenado o la consulta parametrizada a la
que vaya a invocar, puede utilizar el método Createparameter
para crear objetos Parameter con los valores apropiados y utilizar
el método Append para agregarlos a la colección Parameters.
Esto le permite establecer y obtener valores de parámetros
sin tener que invocar el método Refresh de la colección
Parameters para obtener información de los parámetros
desde el proveedor, una operación que potencialmente consume
bastantes recursos. |
| |
| Propiedades |
| |
Propiedad
Attributes (ADO), Propiedad Direction (ADO), Propiedad Name
(ADO>,
Propiedad NumericScale (ADO), Propiedad Precision (ADO), Propiedad
Size (ADO), Propiedad Type (ADO), Propiedad Value (ADO).
|
| |
| Métodos |
| |
Método
AppendChunk (ADO), Método Delete (Colección de parámetros
ADO), Método Delete (Conjunto de Registros ADO). |
| |
| Colecciones |
| |
| Colección
Properties. |
| |
| Recordset,
objeto (ADO) |
| |
Un
objeto Recordset representa todo el conjunto de registros de
una tabla
o del resultado de un comando ejecutado. En cualquier momento,
el objeto Recordset sólo hace referencia a un único
registro dentro del conjunto, llamado registro actual. |
| |
Los
objetos Recordset se utilizan para manipular los datos de un
proveedor.
Cuando se utiliza ADO, se manipulan los datos casi completamente
con objetos Recordset. Tollos los objetos Recordset se construyen
utilizando registros (filas) y campos (columnas). Dependiendo
de
la funcionalidad aceptada por el proveedor, algunos métodos
o propiedades del objeto Recordset puede que no estén
disponibles. |
| |
|
ADOR.Recordset
y ADODB.Recordset son ProgID que se utilizan para crear objetos
Recordset. Los objetos Recordset que resultan se comportan de
forma idéntica, independientemente del ProgID. ADOR.Recordset
se instala con Internet Explorer de Microsoft®; ADODB.Recordset
se instala con ADO. El comportamiento de un objeto Recordset esta
afectado por su entorno (esto es, cliente, servidor, Internet
Explorer, etc.). Las diferencias se describen en los temas de
Ayuda de sus propiedades. métodos y eventos. Hay cuatro
tipos diferentes de cursores en ADO:
-
Cursor
dinámico: le permite ver inserciones, modificaciones
y eliminaciones de otros usuarios, y permite todos los tipos
de movimientos a través del Recordset que estén
relacionados con marcadores; permite marcadores si el proveedor
los acepta.
-
Cursor
de conjunto de claves: se comporta como un cursor dinámico,
excepto que impide ver registros agregados por otros usuarios,
e impide el acceso a registros eliminados por otros usuarios.
Las modificaciones en los datos efectuadas por otros usuarios
siguen siendo visibles. Acepta siempre marcadores y, por tanto,
permite todos los tipos de movimientos a través del
Recordset.
-
Cursor
estático: proporciona una copia estática de un
conjunto de registros para que se utilicen en búsquedas
de datos o para generar informes; permite siempre los marcadores
y, por tanto, permite todos los tipos de movimientos a través
del Recordset. Las inserciones, modificaciones o eliminaciones
efectuadas por otros usuarios no serán visibles. Este
es el único tipo de cursor permitido cuando se abre
un objeto Recordset en el lado del cliente (ADOR).
-
Cursor
de tipo Forward-only: se comporta de forma idéntica al
cursor dinámico, excepto en que sólo le permite
recorrer los registros hacia delante. Esto aumenta el rendimiento
en situaciones en las que sólo tenga que efectuar un
paso a través de un Recordset.
|
Establezca
la propiedad CursorType antes de abrir el Recordset para elegir
el tipo de cursor, o pase un argumento CursorType con el método
Open. Algunos proveedores no aceptan todos los tipos de cursores.
Compruebe la documentación del proveedor. Si no se especifica
el tipo del cursor, ADO abre un cursor de tipo Forward-only de manera
predeterminada. Cuando se utilizan con algunos proveedores (como
Microsoft ODBC Provider para OLE DB junto con Microsoft SQL Server),
se pueden crear objetos Recordset independientemente de un objeto
Connection definido previamente pasando una cadena de conexión
al método Open. ADO sigue creando un objeto Connection, pero
no asigna dicho objeto a una variable de objeto. Sin embargo, si
se están abriendo varios objetos Recordset en la misma conexión,
se tiene que crear y abrir explícitamente un objeto Connection;
así se asigna el objeto Connection a una variable de objeto.
Si no se utiliza dicha variable de objeto cuando se abren los objetos
Recordset, ADO crea un nuevo objeto Connection por cada nuevo Recordset,
incluso si se pasa la misma cadena de conexión. Se pueden
crear tantos objetos Recordset como sea necesario. Cuando se abre
un Recordset, el registro actual está situado en el primer
registro (si lo hay) y las propiedades BOBy EOF están establecidas
a False. Si no hay registros, los valores de las propiedades BOF
y EOF son True. Pueden utilizarse los métodos Movelfirst,
MoveLast, MoveNext y MovePrevious, así como el método
Move, y las propiedades AbsolutePosition, AbsolutePage y Filter
para volver a colocar el registro actual, asumiendo que el proveedor
acepta la funcionalidad necesaria. Los objetos Recordset de tipo
Forward-only sólo aceptan el método MoveNext. Cuando
se utilizan métodos Move para visitar todos los registros
(o para enumerar el Recordset), se puede utilizar las propiedades
BOF y EOF para saber si ha llegado al principio o al final del Recordset.
Los objetos Recordset pueden aceptar dos tipos de actualización:
inmediata y por lotes. En la actualización inmediata, todas
las modificaciones se escriben inmediatamente en el origen de datos
después de invocar el método Update. También
se pueden pasar matrices de valores como parámetros en los
métodos AddNew y Update y actualizar de forma simultánea
varios campos de un registro. Si un proveedor acepta la actualización
por lotes, se puede hacer que el proveedor guarde en la caché
las modificaciones efectuadas en varios registros y transmitirlos
después en una sola llamada a la base de datos con el método
UpdateBatch. Esto se aplica a las modificaciones efectuadas con
los métodos AddNew, Update y Delete. Después de invocar
el método UpdateBatch, se puede utilizar la propiedad Status
para comprobar si ha habido algún conflicto en los datos
para resolverlo. |
| |
Nota:
Para ejecutar una consulta sin utilizar un objeto Command,
pase
una cadena de consulta al método Open de un objeto Recordset.
Sin embargo. se requiere un objeto Command cuando quiera que el
texto del comando persista para volver a ejecutarlo, o cuando utilice
parámetros en la consulta. |
| |
| Propiedades |
| |
Propiedad
AbsolutePage (ADO), Propiedad AbsolutePosition (ADO), Propiedad
ActiveConnection (ADO), Propiedad BOF, EOF (ADO), Propiedad Bookmark
(ADO), Propiedad CacheSize (ADO), Propiedad CursorLocation (ADO),
Propiedad CursorType (ADO), Propiedad EditMode (ADO), Propiedad
F'ilter (ADO), Propiedad LockType (ADO), Propiedad MarshalOption
(ADO), Propiedad MaxRecords (ADO), Propiedad PageCount (ADO), Propiedad
PageSize (ADO), Propiedad RecordCount (ADO), Propiedad Source (Conjunto
de Registros ADO), Propiedad State (ADO), Propiedad Status (ADO). |
| |
| Métodos |
| |
Método
AddNew (ADO), Método Cancel (ADO), Método CancelBatch
(ADO), Método CancelUpdate (ADO), Método Clone (ADO),
Método Delete (Colección de parámetros ADO).
Método Delete (Colección de campos ADO), Método
Delete (Conjunto dc registros ADO), Método Move (ADO), Métodos
MoveFirst, MoveLast, MoveNext y MovePrevious (ADO), Método
NextRecordset (ADO), Método Open (Conexión ADO) Método
Open (Conjunto de regi~tros ADO), Método Requery (ADO), Método
Resync (ADO), Método Save (Conjunto de registros ADO), Método
Supports (ADO). Método Update (ADO), Método UpdateBatch
(ADO). |
| |
| Propiedades
ADO |
| |
| AbsolutePage,
propiedad (ADO) |
| |
| Especifica
en qué página reside el registro actual. |
| |
| Se aplica
a Objeto Recordset (ADO). |
| |
Configuración
y valores devueltos
Establece o devuelve un valor de tipo Long entre 1 y el número
Recordset (PageCount) o devuelve una de las constantes siguientes:
| adPosUnknown |
El
objeto Recordset está vacío, la posición
actual se desconoce o el proveedor no admite la propiedad
AbsoltitePage. |
| adPosBOF |
El
puntero del registro actual está al comienzo del archivo
(C5 decir, la propiedad BOF tiene el valor True). |
| adPosEOF |
El
puntero del registro actual está al final del archivo
(es decir, la propiedad EOF tiene el valor True). |
|
| |
Utilice
la propiedad AbsolutePage para identificar el número de la
página en que se encuentra el registro actual. Utilice la
propiedad PageSize para dividir lógicamente el objeto Recordset
en varias páginas, cada una de las cuales debe tener un número
de registros igual a PageSize (excepto la última página,
que puede tener menos registros). El proveedor debe ser compatible
con la funcionalidad apropiada para que esta propiedad esté
disponible. Al igual que la propiedad AbsolutePosition, la propiedad
AbsolutePage está en base 1 v es igual a 1 cuando el registro
actual es el primer registro del objeto Recordset. Establezca esta
propiedad para moverse al primer registro de una página específica.
Obtenga el número total de páginas a partir de
la propiedad PageCount. |
| |
| AbsolutePosition,
propiedad (ADO) |
| |
| Especifica
la posición ordinal del registro actual de un objeto Recordset. |
| |
| Se aplica
a |
| |
| Objeto
Recordset (ADO). |
| |
| Configuración
y valores devueltos |
| |
Establece
o devuelve un valor de tipo Long entre 1 y el número de registros
del objeto Recordset (RecordCount) o devuelve una de las constantes
siguientes: Constante Descripción
| adPosUnknown
|
El
objeto Recordset está vacío, la posición
actual se desconoce o el proveedor no admite la propiedad
AbsoltitePage. |
| adPosBOF |
El
puntero del registro actual está al comienzo del
archivo (C5 decir, la propiedad BOF tiene el valor True). |
| adPosEOF |
El
puntero del registro actual está al final del
archivo (es decir, la propiedad EOF tiene el valor True). |
|
| |
Utilice
la propiedad AbsolutePosition para moverse a un registro según
su posición ordinal en el objeto Recordset o para determinar
la posición ordinal del registro actual. El proveedor debe
ser compatible con la funcionalidad apropiada para que esta propiedad
esté disponible. Al igual que la propiedad AbsolutePage,
la propiedad AbsolutePosition está en base 1 y es igual a
1 cuando el registro actual es el púrner registro del objeto
Recordset. Puede obtener el número total de registros contenidos
en dicho objeto Recordset a partir de la propiedad RecordCount.
Cuando establece la propiedad AbsoiutePos¡tion, incluso si
es para un registro contenido en la memoria caché actual,
ADO vuelve a cargar la memoria caché con un nuevo grupo de
registros que comienza con el registro especificado. La propiedad
CacheSize determina el tamaño de este grupo. |
| |
Nota:
No debería utilizar la propiedad AbsolutePosition como un
número de registro sustirntorio. La posición de un
registro dado cambia cuando se elimina un registro anterior Tampoco
hay ninguna seguridad de que un registro dado tendrá la misma
propiedad AbsolutePosition si se vuelve a consultar o se vuelve
a abrir el objeto Recordset. Los marcadores siguen siendo la forma
recomendada para conservar y volver a una posición dada,
v son la única manera de posicionamiento en todos los
tipos de objetos Recordset. |
| |
| Ejemplo |
| |
Este
ejemplo muestra cómo la propiedad AbsolutePosition puede
llevar cuenta del progreso de un bucle que enumera todos los
registros
de un Recordset. Utiliza la propiedad CursorLocation para habilitar
la propiedad AbsolutePosition ajustando el cursor a un cursor
de
cliente: |
| |
Public
Sub AbsolutePositionX()
| |
Dim
rstEmployees As ADODB.Recordset
Dim strCnn As String
Dim strMessage As String |
| |
|
| |
'
Open a recordset for the Employee table
' using a client cursor.
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=;
" |
|
| |
Set
rstEmployees = New ADODB.Recordset
' Use client cursor to enable AbsolutePosition property.
rstEmployees.CursorLocation = adUseClient
rstEmployees.Open "employee", strCnn, , , adCmdTable
|
| |
|
| |
'
Enumerate Recordset.
Do While Not rstEmployees.EOF
| |
'
Display current record information.
strMessage = "Employee: " & rstEmployees!lName
& vbCr & _
| |
"(record
" & rstEmployees.AbsolutePosition &
_
" of " & rstEmployees.RecordCount
& ")" |
If
MsgBox(strMessage, vbOKCancel) = vbCancel _
rstEmployees.MoveNext
|
Loop
rstEmployees.Close |
End Sub
|
| |
BOF
indica que la posición del registro actual está antes
del primer registro de un objeto Recordset EOF indica que la posición
del registro actual esta después del último registro
de un objeto Recordset. |
| |
| Valor
devuelto |
| |
Las
propiedades BOF y EOF devuelven valores Boolean.
Se aplica a Objeto Recordset ADO. |
| |
Utilice
las propiedades BOF y BOF para determinar si un objeto Recordset
contiene registros o si se han sobrepasado los límites
de un objeto Recordset al moverse de un registro a otro.
La propiedad BOF devuelve True (-1) si la posición del registro
actual está antes del primer registro, y devuelve False (O)
si la posición del retristro actual esta en o después
del primer registro. |
| |
La
propiedad EOF devuelve True si la posición del registro actual está
después del último registro, y devuelve False si la
posición del registro actual está en o después
del último registro.
Si una de las dos propiedades BOF o EOF es true. no hay ningún
registro actual.
Si se abre un objeto Recordset que no contiene registros las propiedades
BOF y EOF se establecen a True y el valor de la propiedad RecordCount
del objeto Recordset es cero.
Cuando se abre un objeto Recordset que contiene. al menos. un registro.
el primer registro es el registro actual y las propiedades BOF y
BOF tienen el valor False.
Si se elimina el último registro que queda en el objeto
Recordset, las propiedades BOF y EOF pueden conservar el valor
False hasta
que se intente volver a colocar el registro actual.
Esta tabla muestra qué métodos Move se permiten
con diferentes combinaciones de las propiedades BOF y EOF:
| |
MoveFirst,
MoveLast |
MovePrevious,
Move<O |
Move
O |
MoveNext,Move>O |
| BOF=True,EOF=False |
Permitido |
Error |
Error |
Permitido |
| BOF=False,EOF=True
|
Permitido |
Permitido |
Error |
Error |
| Ambas
True |
Error |
Error |
Error |
Error |
| Ambas
False |
Permitido |
Permitido |
Permitido |
Permitido |
|
| |
Permitir
un método Move no garantiza que el método localizará
correctamente un registro, sólo significa que al llamar al
método Move especificado no se producirá un error.
La tabla siguiente muestra qué ocurre en los valores de las
propiedades BOF y EOF cuando se llama a varios métodos
Move, pero no puede localizar correctamente un registro:
| |
BOF |
EOF |
| MoveFirst,
MoveLast |
Se
establece a True. |
Se
establece a True. |
| Move
O |
Ningún
cambio |
Ningún
cambio |
| MovePrevious,
Move <O |
Se
establece a True. |
Ningún
cambio |
| MoveNext,
Move > O |
Ningún
cambio |
Se
establece a True. |
|
| |
| E¡emplo |
| |
Este
ejemplo utiliza las propiedades BOF y EOF para visualizar un
mensaje
si un usuario intenta desplazarse más allá del primer
o último registro de un Recordset. Utiliza la propiedad Bookmark
para permitir al usuario etiquetar un registro en un Recordset y
volver a él más tarde: |
| |
Public
Sub BOFX()
| |
Dim
rstPublishers As ADODB.Recordset
Dim strCnn As String
Dim strMessage As String
Dim intCommand As Integer
Dim varBookmark As Variant |
| |
|
| |
'
Open recordset with data from Publishers table.
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=;
" |
Set
rstPublishers = New ADODB.Recordset
rstPublishers.CursorType = adOpenStatic
' Use client cursor to enable AbsolutePosition property.
rstPublishers.CursorLocation = adUseClient
rstPublishers.Open "SELECT pub_id, pub_name FROM publishers
" & _
| |
"ORDER
BY pub_name", strCnn, , , adCmdText |
|
| |
|
| |
rstPublishers.MoveFirst |
| |
|
| |
Do
While True
| |
'
Display information about current record
' and get user input.
strMessage = "Publisher: " & rstPublishers!pub_name
& _
| |
vbCr
& "(record " & rstPublishers.AbsolutePosition
& _
" of " & rstPublishers.RecordCount
& ")" & vbCr & vbCr &
_
"Enter command:" & vbCr & _
"[1 - next / 2 - previous /" & vbCr
& _
"3 - set bookmark / 4 - go to bookmark]"
|
intCommand
= Val(InputBox(strMessage)) |
| |
|
| |
Select
Case intCommand
| |
'
Move forward or backward, trapping for BOF
' or EOF.
Case 1
| |
rstPublishers.MoveNext
If rstPublishers.EOF Then
| |
MsgBox "Moving past the last
record." & _
rstPublishers.MoveLast
|
End
If |
|
| |
Case 2
| |
rstPublishers.MovePrevious
If rstPublishers.BOF Then
| |
MsgBox
"Moving past the first record."
& _
rstPublishers.MoveFirst
|
End
If |
|
| |
'
Store the bookmark of the current record.
Case 3
| |
varBookmark
= rstPublishers.Bookmark |
'
Go to the record indicated by the stored
' bookmark. |
| |
Case
4
| |
If IsEmpty(varBookmark) Then
| |
MsgBox
"No Bookmark set!" |
Else
| |
rstPublishers.Bookmark = varBookmark |
End
If |
|
| |
|
| |
Case Else
|
End
Select |
Loop
rstPublishers.Close |
End Sub
|
| |
Este
ejemplo utiliza las propiedades Bookmark y Filter para crear
una
vista limitada del Recordset. Sólo son accesibles los
registros referenciados por la matriz de marcadores: |
| |
Public
Sub BOFX2()
Dim rs
As New ADODB.Recordset
Dim bmk(10)
rs.CursorLocation
= adUseClient
rs.ActiveConnection = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=;"
|
rs.Open
"select * from authors", , adOpenStatic, adLockBatchOptimistic
Debug.Print "Number of records before filtering: ", rs.RecordCount
ii = 0
While rs.EOF <> True And ii < 11
| |
bmk(ii)
= rs.Bookmark
ii = ii + 1
rs.Move 2 |
Wend
rs.Filter = bmk
Debug.Print "Number of records after filtering: ", rs.RecordCount
rs.MoveFirst
While rs.EOF <> True
| |
Debug.Print
rs.AbsolutePosition, rs("au_lname")
rs.MoveNext |
Wend
End Sub
|
| |
| CommandTimeout,
propiedad (ADO) Descripción |
| |
| Indica
el intervalo de espera para que se ejecute un comando antes de que
finalice el intento y se genere un error. |
| |
| Se aplica
a |
| |
Objeto
Command (ADO), Objeto Connection (ADO).
Configuración y valores devueltos |
| |
Establece
o devuelve un valor Long que indica, en segundos, el intervalo de
espera para que se ejecute un comando. El valor predeterminado es
30. |
| |
| Comentarios
|
| |
Use
la propiedad CommandTimeout en un objeto Connection o en un
objeto
Command para permitir la cancelación de una llamada al método
Execute, debida a demoras en el tráfico de la red o a una
sobrecarga en el servidor. Si transcurre el intervalo establecido
en la propiedad CommandTimeout antes de que termine la ejecución
de la orden, se produce un error y ADO cancela el comando. Si establece
la propiedad a cero, ADO esperará indefinidamente hasta que
termine la ejecución. Compruebe que el proveedor y el origen
de datos para los que está escribiendo código admiten
la funcionalidad CommandTimeout. El valor de CommandTimieout en
un objeto Connection no afecta al valor de CommandTimeout en un
objeto Command de la misma Connection,. es decir, la propiedad CommandTimeout
del objeto Command no hereda el valor de CommandTimeout del objeto
Connection. En un objeto Connection, la propiedad CommandTimeout
permanece en modo lectura/escritura después de que se
abra Connection. |
| |
| ConnectionString,
propiedad (ADO) |
| |
| Contiene la
información que se utiliza para establecer
una conexión a un origen de datos. |
| |
| Se aplica a |
| |
| Objeto Connection (ADO). |
| |
| Configuración
y valores devueltos |
| |
| Establece o devuelve un valor String. |
| |
Use
la propiedad ConnectionString para especificar un origen de
datos pasando
una cadena de conexión detallada que contenga
una serie de instrucciones argumento = valor separadas con punto
y coma. |
| |
ADO admite cuatro argumentos con la propiedad ConnectionString;
cualquier otro argumento pasa directamente al proveedor sin que
ADO lo procese. Los argumentos compatibles con ADO son los siguientes:
| Argumento |
Descripción |
| Provider= |
Especifica el nombre del proveedor que se usa con la conexion |
| File Name= |
Indica
el nombre de un archivo especifico del proveedor (por
Qíempío, un objeto de origen de datos persistente)
que contiene información sobre la conexión
preestablecida. |
| Remote provider= |
Especifica
el nombre de un proveedor que se usa al abrir una conexión
del lado del cliente (solamente con Remote Data Service). |
| Remote Server= |
Especifica
la ruta de acceso del servidor que se usa al abrir una
conexión del lado del cliente (solamente
con Remote Data Service). |
|
| |
Argumento
Descripción Provider Especifica el nombre del
proveedor que se usa con la conexion. Indica el nombre de un archivo
especifico del proveedor (por Qíempío, un objeto de
origen de datos persistente) que contiene información sobre
la conexión preestablecida. File Name Remote provider |
| |
Especifica
el nombre de un proveedor que se usa al abrir una conexión
del lado del cliente (solamente con Remote Data Service). |
| |
Remote
Server Especifica la ruta de acceso del servidor que se usa
al abrir
una conexión del lado del cliente (solamente
con Remote Data Service). |
| |
Después de que se establezca la propiedad ConnectionString
y se abra el objeto Connection. es posible que el proveedor modifique
el contenido de la propiedad: por ejemplo, asignando los nombres
de argumento definidos con ADO a sus equivalentes en el proveedor.
La propiedad ConnectionString hereda automáticamente el valor
que se utiliza con el argumento Connections del método Open
para que se pueda hacer caso omiso de la propiedad connectionString
actual durante la llamada al método Open. Debido a que el
argumento File Name hace que ADO cargue el proveedor asociado. no
se pueden pasar ambos argumentos, Provider y File Name. La propiedad
ConnectionString es de lectura/escútura cuando la conexión
está cerrada y de sólo lectura cuando está abierta. |
| |
| Count, propiedad (ADO) |
| |
| Indica el número
de objetos de una coleccion. |
| |
| Devuelve un valor Long. |
| |
| Se aplica a |
| |
| Colección Errors (ADO). Colección Fields (ADO) Colección
Parameter (ADO). Colección Properties (ADO). |
| |
Use
la propiedad Count para determinar cuántos objetos
hay en una colección dada. Debido a que la numeración
de miembros de una colección empieza por cero, debe codificar
siempre los bucles empezando siempre con el miembro cero y terminando
con el valor de la propiedad Count menos 1. Si está usando
Microsoft Visual Basic y desea hacer un recorrido por los miembros
de una colección sin comprobar la propiedad Count use el
comando For Each...Next. Si la propiedad Count es cero. no hay ningún
objeto en la colección. |
| |
| CursorLocation,
propiedad (ADO) Descripción |
| |
| Establece o
devuelve la posición de un motor de cursores. |
| |
| Se aplica a |
| |
| Objeto Connection (ADO), Objeto Recordset (ADO). |
| |
Establece o devuelve un valor Long que se puede establecer a alguna
de las siguientes constantes:
| Constante |
Descripción |
| adUseNone |
No
se usan servicios de cursor. (Esta constante es obsoleta
y
aparece únicamente por compatibilidad con versiones
anteriores.) |
| adUseClient |
Usa
cursores del lado del cliente suministrados por una biblioteca
de
cursores locales. Los motores de cursores locales
admitirán a menudo muchas características que
los cursores proporcionados por controladores no admitirán;
por tanto, el uso de esta configuración puede proporcionar
una ventaja con respecto a características que serán
habilitadas. Por compatibilidad con versiones anteriores.
se admite también el sinónimo adUseClientBatch. |
| adUseServer |
Predeterminado.
Usa cursores suministrados por el controlador o por
el proveedor de datos. Estos cursores son, en ocasiones.
muy flexibles y conceden un margen de sensibilidad adicional
a los cambios realizados por otros usuarios en el origen
de
datos. No obstante. algunas características de Microsoft
Client Cursor Provider (como los conjuntos de registros disociados)
no pueden ser simuladas con cursores del lado del servidor
y no estarán disponibles con esta configuración. |
|
| |
Esta propiedad le permite elegir entre distintas bibliotecas de
cursores accesibles para el proveedor. Normalmente, puede elegir
entre usar una biblioteca de cursores del lado del cliente o una
ubicada en el servidor. |
| |
El
valor de esta propiedad afecta solamente a las conexiones establecidas
después de que se haya establecido la propiedad. Los cambios
en la propiedad CursorLocation no afectan a las conexiones existentes.
Esta propiedad es de lectura/escritura en un Connection o Recordset
cerrado, y de sólo lectura en un Recordset abierto. Los cursores
de Connection.Execute heredarán esta configuración.
Los objetos Recordset heredarán automáticamente esta
configuración de sus conexiones asociadas. |
| |
Uso
de Remote Data Service. Cuando se usa en un objeto Recordset
o Connection
(ADOR) del lado del cliente, la propiedad CursorLocation
sólo se puede establecer a adUseClient: |
| |
| Direction, propiedad (ADO) |
| |
Indica
si Parameter representa un parámetro de entrada,
un parámetro de salida o ambos bien, si el parámetro
es el valor devuelto por un procedimiento almacenado. |
| |
| Se aplica a |
| |
| Objeto Parameter (ADO). |
| |
Establece o devuelve uno de los siguientes valores
de ParameterDirectionEnum:
| Constante |
Descripción |
| adParamUnknown |
Indica
que la dirección del parámetro es desconocida. |
| adParamlnput |
Valor
predeterminado. Indica un parámetro de entrada. |
| adParamOutput |
Indica
un parámetro de salida. |
| adParamlnputOutput |
Indica
un parámetro de entrada y otro de salida. |
| adParamReturnValue |
Indica un valor devuelto. |
|
| |
Utilice
la propiedad Direction para especificar cómo se
pasa un parámetro hacia o desde un procedimiento. La propiedad
Direction es de lectura/escritura; esto le permite trabajar con
proveedores que no devuelven esta información o establecer
esta información cuando desea que ADO realice una llamada
adicional al proveedor para recuperar información acerca
del parámetro. No todos los proveedores pueden determinar
la dirección de los parámetros en sus procedimientos
almacenados. En estos casos, debe establecer la propiedad Direction
antes Ejecutar la consulta. |
| |
| Ejemplo |
| |
Este ejemplo utiliza las propiedades ActiveConnection, CommandText,
CommandTimeout, CommandType. Size y Direction para ejecutar un procedimiento
almacenado: |
| |
Public Sub ActiveConnectionX()
Dim cnn1 As ADODB.Connection
Dim cmdByRoyalty As ADODB.Command
Dim prmByRoyalty As ADODB.Parameter
Dim rstByRoyalty As ADODB.Recordset
Dim rstAuthors As ADODB.Recordset
Dim intRoyalty As Integer
Dim strAuthorID As String
Dim strCnn As String
' Define a command object for a stored procedure.
Set cnn1 = New ADODB.Connection
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=; " |
cnn1.Open strCnn
Set cmdByRoyalty = New ADODB.Command
Set cmdByRoyalty.ActiveConnection = cnn1
cmdByRoyalty.CommandText = "byroyalty"
cmdByRoyalty.CommandType = adCmdStoredProc
cmdByRoyalty.CommandTimeout = 15
' Define the stored procedure's input parameter.
intRoyalty = Trim(InputBox( _
Set prmByRoyalty = New ADODB.Parameter
prmByRoyalty.Type = adInteger
prmByRoyalty.Size = 3
prmByRoyalty.Direction = adParamInput
prmByRoyalty.Value = intRoyalty
cmdByRoyalty.Parameters.Append prmByRoyalty
' Create a recordset by executing the command.
Set rstByRoyalty = cmdByRoyalty.Execute()
' Open the Authors table to get author names for display.
Set rstAuthors = New ADODB.Recordset
rstAuthors.Open "authors", strCnn, , , adCmdTable
' Print current data in the recordset, adding
' author names from Authors table.
Debug.Print "Authors with " & intRoyalty & _
Do While Not rstByRoyalty.EOF
| |
strAuthorID = rstByRoyalty!au_id
Debug.Print , rstByRoyalty!au_id & ", ";
rstAuthors.Filter = "au_id = '" & strAuthorID
& "'"
Debug.Print rstAuthors!au_fname & " " & _
rstByRoyalty.MoveNext |
Loop
| |
rstByRoyalty.Close
rstAuthors.Close
cnn1.Close |
End Sub |
| |
| PageCount, propiedad (ADO) |
| |
| Indica cuántas páginas
de datos contiene el objeto Recordset. |
| |
| Se aplica a |
| |
Objeto Recordset (ADO).
Devuelve un valor de tipo Long. |
| |
Utilice
la propiedad PageCount para determinar cuántas
páginas de datos hay en el objeto Recordset. Las páginas
son grupos de registros cuyo tamaño es igual al valor de
la propiedad PageSize. Incluso si la última página
no está completa, debido a que hay menos regístros
que el valor de la propiedad PageSize, se cuenta como una página
adicional en el valor de PageCount. |
| |
Si
el objeto Recordset no admite esta propiedad, el valor será
-l para indicar que no se puede determinar el valor de PageCount.
Vea las propiedades PageSize y AbsolutePage para obtener más
información acerca de la funcionalidad de las páginas. |
| |
| Ejemplo |
| |
Este ejemplo utiliza las propiedades AbsolutePage, PageCount y
PageSize para visualizar nombres y tomar fechas de la tabla Empleado
cinco registros cada vez: |
| |
Public Sub AbsolutePageX()
| |
Dim rstEmployees As ADODB.Recordset
Dim strCnn As String
Dim strMessage As String
Dim intPage As Integer
Dim intPageCount As Integer
Dim intRecord As Integer
' Open a recordset using a client cursor
' for the employee table.
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=; " |
Set rstEmployees = New ADODB.Recordset
' Use client cursor to enable AbsolutePosition property.
rstEmployees.CursorLocation = adUseClient
rstEmployees.Open "employee", strCnn, , , adCmdTable
' Display names and hire dates, five records
' at a time.
rstEmployees.PageSize = 5
intPageCount = rstEmployees.PageCount
For intPage = 1 To intPageCount
| |
rstEmployees.AbsolutePage = intPage
strMessage = ""
For intRecord = 1 To rstEmployees.PageSize
| |
strMessage
= strMessage & _
| |
rstEmployees!fname & "
" & _
rstEmployees!lname & " " & _
rstEmployees!hire_date & vbCr |
rstEmployees.MoveNext
If rstEmployees.EOF Then Exit For |
Next intRecord
MsgBox strMessage |
Next intPage
rstEmployees.Close |
End Sub |
| |
| PageSize, propiedad (ADO) |
| |
| Indica cuántos registros constituyen una página
en el objeto Recordset. |
| |
| Se aplica a |
| |
| Objeto Recordset (ADO). |
| |
| Establece o
devuelve un valor de tipo Long que indica cuántos
registros hay en una página. El valor predeterminado es
10. |
| |
Utilice
la propiedad PageSize para determinar cuántos registros
componen una página lógica de datos. Al establecer
un tamaño de página, puede utilizar la propiedad AbsolutePage
para moverse al primer registro de una página específica.
Esto es útil en las situaciones de servidor Web cuando se
desea permitir que el usuario pase páginas de datos y vea
cierto número de registros al mismo tiempo. Esta propiedad
se puede establecer en cualquier momento y su valor se utilizará
para calcular la ubicación del primer registro de una página
específica. |
| |
| RecordCount, propiedad (ADO) |
| |
| Indica el número
actual de registros de un objeto Recordset. |
| |
| Se aplica a |
| |
| Objeto Recordset (ADO). |
| |
| Devuelve un valor de tipo Long. |
| |
Utilice
la propiedad RecordCount para averiguar cuántos
registros hay en un objeto Recordset. La propiedad devuelve -1 cuando
ADO no puede determinar el número de registros. Al leer la
propiedad RecordCount de un objeto Recordset cerrado, se produce
un error. Si el objeto Recordset admite el posicionamiento aproximado
o los marcadores, es decir, si las propiedades Supports (adApproxPosition)
o Supports (adBookmark), respectivamente, devuelven True, este valor
será el número exacto de registros del objeto Recordset
independientemente de si se ha llenado completamente. Si el objeto
Recordset no admite el posicionamiento aproximado, esta propiedad
puede consumir muchos recursos debido a que será necesario
recuperar y contar todos los recursos para devolver un valor
preciso de RecordCount. |
| |
| Ejemplo |
| |
Este
ejemplo utiliza la propiedad Filter para abrir un Recordset
nuevo basado
en una condición específica aplicada
a un Recordset existente. Utiliza la propiedad RecordCount para
mostrar el número de registros en los dos Recordsets. Es
necesaria la función FilterField para que funcione este
procedimiento: |
| |
Public Sub FilterX()
| |
Dim rstPublishers As ADODB.Recordset
Dim rstPublishersCountry As ADODB.Recordset
Dim strCnn As String
Dim intPublisherCount As Integer
Dim strCountry As String
Dim strMessage As String |
' Open recordset with data from Publishers table.
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=; " |
Set rstPublishers = New ADODB.Recordset
rstPublishers.CursorType = adOpenStatic
rstPublishers.Open "publishers", strCnn, , , adCmdTable
' Populate the Recordset.
intPublisherCount = rstPublishers.RecordCount
' Get user input.
strCountry = Trim(InputBox( _
| |
"Enter a country to filter on:")) |
If strCountry <> "" Then
| |
' Open a filtered Recordset object.
Set rstPublishersCountry =
| |
FilterField(rstPublishers, "Country",
strCountry) |
If rstPublishersCountry.RecordCount = 0 Then
| |
MsgBox "No
publishers from that country." |
Else
| |
' Print number of records for the original
' Recordset object and the filtered Recordset
' object.
strMessage = "Orders in original recordset: "
& _
| |
vbCr & intPublisherCount &
vbCr & _
"Orders in filtered recordset (Country =
'" & _
strCountry & "'): " & vbCr & _
rstPublishersCountry.RecordCount |
MsgBox strMessage |
End If
rstPublishersCountry.Close
|
.....End If
End Sub
|
| |
| |
Public Function FilterField(rstTemp As ADODB.Recordset, _
| |
strField As String, strFilter As String) As
ADODB.Recordset
' Set a filter on the specified Recordset object and then
' open a new Recordset object.
rstTemp.Filter = strField & " = '" & strFilter
& "'"
Set FilterField = rstTemp |
End Function |
| |
Nota:
Cuando sabe los datos que desea seleccionar, suele ser más
eficiente abrir un Recordset con una sentencia SQL. Este ejemplo
muestra cómo puede crear un único Recordset y obtener
registros de un país en particular. |
| |
Public Sub FilterX2()
| |
Dim rstPublishers As ADODB.Recordset
Dim strCnn As String
' Open recordset with data from Publishers table.
strCnn = "Provider=sqloledb;" & _
| |
"Data
Source=srv;Initial Catalog= pubs;UserId=sa;Password=; " |
Set rstPublishers = New ADODB.Recordset
rstPublishers.CursorType = adOpenStatic
rstPublishers.Open "SELECT * FROM publishers " & _
| |
"WHERE Country = 'USA'",
strCnn, , , adCmdText |
' Print current data in recordset.
rstPublishers.MoveFirst
Do While Not rstPublishers.EOF
| |
Debug.Print rstPublishers!pub_name &
", " & _
rstPublishers.MoveNext |
Loop
rstPublishers.Close |
End Sub |
| |
| Sort, propiedad (ADO) |
| |
Especifica
uno o más nombres de campos por los que se ordena
el objeto Recordset y si cada campo se ordena de forma ascendente
o descendente.
Configuración y valores devueltos |
| |
Establece
o devuelve un valor de tipo String con los nombres de los campos
utilizados para ordenar separados por comas, donde cada
nombre es un objeto Field del objeto Recordset Y, opcionalmente,
está seguido de un espacio en blanco y de la palabra
clave ASCENDING o DESCENDING, que especifica el orden del campo. |
| |
Los
datos no se vuelven a ordenar físicamente, sino que,
simplemente, se tiene acceso a los mismos en el orden indicado.
Se creará un índice temporal para cada uno de los
campos especificados en la propiedad Sort si la propiedad CursorLocation
se establece a adUseClient y no existe ya un índice. Al establecer
la propiedad Sort a una cadena vacía. se restablecen las
filas a su orden original y se eliminan los índices temporales.
Los índices existentes no se eliminarán. |
| |
v