| Introducción. | |||||
La
recuperación
y la concurrencia están muy interrelacionados ya que ambos
aspectos forman parte del tema más amplio de la administración
de transacciones estas están relacionadas con la cuestión
general de la protección de los datos es decir la protección
contra la perdida o daño de la información que están
en la basa de datos. |
|||||
La
recuperación
de información se realizara al aplicar consultas a bases
de datos, esperando que el resultado aumente el conocimiento del
usuario. Las aplicaciones de la base de datos que no se considera
de recuperación de información son aquellos sistemas
que proporciona servicio operativo regular, por ejemplo, sistemas
que manejan cronológicamente actividades, manejan inventarios
o preparan facturas o nominas. |
|||||
Cuando
se analiza la recuperación de información no se considera
que la actualización de los archivos sea un problema importante.
Esto simplifica mucho la comparación de los enfoques. Sin
embargo, en la practica del problema de actualización es
importante para cualquier sistema de recuperación de información.
Si el contenido de la información del material en forma impresa
o microfilmada podría ser una mejor alternativa que las
computadoras. |
|||||
| TRANSACCIONES | Volver | ||||
Es
una colección de operaciones que realiza una única función
lógica transacción es una aplicación de base
de datos. Cada transacción es una unidad de atomicidad, una
cuestión importante en el procesamiento de transacciones
de base de datos es la conservación de atomicidad a pesar
de la posibilidad de fallos dentro del sistema de computadores. |
|||||
Es
una unidad del programa que accede y posiblemente actualiza
varios elementos
de información. La transacción lee una sola vez cada
uno de esos elementos de información y en caso de que lo
vaya a actualizar, escribe a lo sumo una vez cada dato exigiendo
que la transacción no viole ninguna restricción
de consistencia de la base de datos. |
|||||
| RECUPERACION DE TRANSACCIONES | Volver | ||||
Una transacción comienza con la ejecución satisfactoria de una instrucción BEGÍN TRANSACTION y termina con la ejecución satisfactoria de una instrucción COMMIT o ROLBACK. COMMIT establece lo que es conocido, entre muchas otras acepciones, como punto de confirmación(también se conoce como punto de sincronización), especialmente en productos comerciales. Un punto de confirmación corresponde entonces al final de una unidad de trabajo lógica y por lo tanto a un punto en el cual la base de datos esta o debería estar en un estado consistente. Por el contrario, ROLLBACK regresa la base de datos al estado EN QUE ESTABA ANTES DE begín transacción, lo que en efecto significa regresar al punto de confirmación anterior. |
|||||
| Al establecer un punto de confirmación : | |||||
1.-Todas
las actualizaciones hechas por el programa en ejecución desde
el punto de confirmación anterior, son confirmadas; es decir,
se vuelven permanentes. Antes del punto de confirmación,
todas estas actualizaciones deben ser vistas como meramente tentativas,
en el sentido de que pueden ser deshechas posteriormente. Es un
hecho que una vez que una transacción ha sido confirmada
nunca podrá ser deshecha. |
|||||
2.-Todo
el posicionamiento de la base de datos se pierde y todos los
bloqueos
de tuplas son liberados. El "posicionamiento de la base de
datos" se refiere en este caso a la idea de que en cualquier
momento, un programa en ejecución tendrá una direccionabilidad
hacia ciertas tuplas son liberados. El "posicionamiento de
la base de datos" se refiere en este caso a la idea de que
en cualquier momento, un programa en ejecución tendrá
una direccionabilidad hacia ciertas tuplas; esta direccionabilidad
se pierde en un punto de confirmación. |
|||||
Algunos
sistemas proporcionan una opción por la cual el programa
puede conservar la direccionabilidad hacia determinadas tuplas y
por lo tanto conservar determinados bloqueos de tuplas entre una
transacción y la siguiente. También se aplica cuando
la transacción termina con ROLLBACK en vez de COMMIT.
|
|||||
| FALLAS DEL SISTEMA | Volver | ||||
Fallas
del sistema: Afectan a todas las transacciones que están
actualmente en progreso, pero dañan físicamente a
la base de datos.(Ejemplo: Falla de suministro eléctrico). |
|||||
El
sistema debe estar preparado para recuperarse, no solamente
de las fallas
puramente locales, como una condición de desborde dentro
de una transacción individual, sino también de las
"fallas globales", como una falla en el suministro eléctrico. |
|||||
| Una falla local afecta solamente a la transacción en la cual esta ocurriendo. | |||||
| Una falla global afecta a todas las transacciones que están en progreso en el momento de la misma. | |||||
La
parte central con relación a la falla del sistema es que
"se pierde el contenido de la memoria principal". Ya no
es posible conocer el estado preciso de cualquier transacción
que estaba en progreso en el momento de la falla y por lo tanto,
tal transacción nunca podrá terminar satisfactoriamente
y deberá ser desecha cuando el sistema vuelva a iniciar. |
|||||
Talvez
sea necesario al momento del reinicio volver a realizar determinadas
transacciones que se complementaron satisfactoriamente antes
de
la falla, pero que no pudieron lograr que sus actualizaciones
fueran transferidas desde los buffers de la Base de Datos,
hacia la Base
de Datos física. |
|||||
Si
el sistema falla, en cualquier paso del sistema global en proceso
de
decisión, observara la decisión registrada en la bitácora
del coordinador. Al encontrar la decisión puede retornarse
el proceso de comando, en donde se dejo. Si no se encuentra registrado
el commit puede asumirse que se dio la orden de cancelar. El
coordinador
puede mantener en espera a un participante durante mucho tiempo,
en ese tiempo debe garantizarse que el participante puede atender
concurrentemente otras transacciones . |
|||||
| ¿Cómo sabe el sistema qué transacciones debe deshacer y cuáles rehacer al momento del reinicio?. | |||||
A
determinados intervalos preescritos, por lo general cuando
ya escrito una determinada
cantidad de entradas en la bitácora, el sistema se hace un
"punto de verificación." Este punto de verificación
involucra: |
|||||
| a).- Escribir físicamente el contenido de los buffers de la Base de Datos hacia la Base de Datos Física. | |||||
| b).- Escribir físicamente un "registro de punto de verificación" especial en la bitácora física | |||||
| FALLAS EN EL MEDIO | |||||
Son
las que causan daño a la Base de Datos o alguna parte de
ella, y afectan al menos a las transacciones que están
usando actualmente es esa parte. (Ejemplo: roce de cabezas en
el disco). |
|||||
Una
falla en el medio podría ser un roce de cabezas o una falla
del controlador del disco, en la cual parte de la Base de Datos
se destruyen físicamente. En general la recuperación
de este tipo de fallas implica básicamente volver a cargar
(o restaurar la Base de Datos) a partir de una copia de seguridad
(o respaldo) y luego usar la bitácora para volver a hacer
todas las transacciones que se terminaron a partir de que se realizó el
respaldo. |
|||||
No
hay necesidad de deshacer transacciones que estaban al progreso
del momento de la falla, ya que por definición todas las
actualizaciones de esas transacciones ya han sido deshechas (de
hecho se perdieron). La necesidad de poder realizar la recuperación
del medio implica el uso de una utilería de vaciado y restauración
(o descarga / recarga). |
|||||
En
la parte de vaciado de esa utilería se usa para hacer respaldos
de la Base de Datos cuando se requiera. Después que ha habido
una falla en el medio, se usa la restauración de la utilería
para volver a crear la Base de Datos a partir de un respaldo específico. |
|||||
| CONCURRENCIA | Volver | ||||
|
|||||
El
término
de concurrencia se refiere al hecho de que los sistemas de bases
de datos normalmente permiten que muchas transacciones tengan
acceso
a los mismos datos, al mismo tiempo. |
|||||
En dichos
sistemas se requieren de mecanismos de control de la concurrencia
para asegurar que las transacciones concurrentes no interfieran
entre si. |
|||||
| PROBLEMAS QUE SE PRESENTAN EN LA CONCURRENCIA | Volver | ||||
Existen
tres formas en que una transacción, aunque sea correcta por
si misma, pueda producir una respuesta incorrecta si alguna otra
transacción interfiere con ella en alguna forma. Obsérvese
que la transacción que interfiere, también puede
ser correcta por si mismo, lo que produce el resultado incorrecto
general,
es el intervalo sin control de las operaciones de las dos transacciones
correctas. |
|||||
Los
tres problemas principales de la concurrencia son:
|
|||||
| Actualización perdida. | |||||
Este
problema puede presentarse si dos transacciones concurrencia actualizan
una misma tupla. Y la segunda que se realiza al final, no toma en
cuenta el efecto de la primera. |
|||||
| Dependencia no comandada. | |||||
Ocurre
si se permita que una transacción lea o modifique una tupla
que ha sido modificada por otra transacción, que sin que
se haya comandado el registro en firme de esta modificación.
Si ocurriera una operación de cancelación podrían
generarse inconsistencias. |
|||||
| Análisis inconsistente. | |||||
Ocurre
cuando una transacción hace un análisis contable o
estadístico, sobre una tabla que esta siendo actualizada
por otra transacción |
|||||
| SERIABILIDAD | |||||
No
existiría
ninguna interferencia si cada transacción esperara hasta
que su predecesora concluyera. A tal manejo se le denomina serial.
Sin embargo él desempeño del sistema se vería
muy disminuido, ya que no podría ocurrir ningún traslape
de cálculos o dispositivos. Se desea permitir él traslape
de las transacciones que sigan dando respuestas correctas y dejen
a la base de datos en un estado correcto. Este seria el caso si
el orden de ejecución de las operaciones primitivas del conjunto
de transacciones que se traslapa diera un resultado que fuera equivalente
a algún manejo cronológico serial de las transacciones
originales. A la propiedad de las transacciones que se traslapan
de tener una programación cronológica correspondiente
en serie sele denomina seriabilidad.
|
|||||
La
seriabilidad se mantendrá si la secuencia de operación de casos
rw y wr cualquiera no se intercambian el caso rr no es sensible
al orden. En el caso ww el valor creado por una transacción
A que traslape se vuelve a escribir debido a la transacción
B, y puede ignorarse si B ha llegado. Rara vez se presentara este
caso ya que indica un mal diseño de transacciones. Las transacciones
que escriben en forma independiente el mismo elemento dado para
un archivo, sin leerlo primero, producirán resultados dependientes
de su tiempo relativo de ejecución. En la practica, resulta
necesaria cierta sincronización. Habrá operaciones
de lectura a los datos o a algún semáforo compartido.
A fin de controlar las secuencias de ejecución. |
|||||
| MECANISMO DE SEGUROS | |||||
| Seguros | |||||
La
solución
a los problemas de integridad consiste en proporcionar un mecanismo
de seguro que asegure las exclusión mutua de transacciones
interferentes. La transacción que solicite primero el
objeto no compartible se vuelve temporalmente la propietaria
de dicho objeto.
Otras transacciones que deseen lograr acceso al objeto se bloquean
hasta que el propietario libere al objeto. |
|||||
| Un mecanismo de seguro | |||||
El
derecho a un objeto se realiza colocando un semáforo. Un semáforo
binario simple consiste en una variable x protegida, que indique
si el recurso asociado esta desocupado u ocupado. Puede colocarse
un semáforo que indique ocupado solo si anteriormente indicaba
que el recurso estaba desocupado. La transacción que posiciona
semáforos se vuelve su propietaria, y solo a ella se le
permite volverlo a posicionar en desocupado. |
|||||
Se
considera que cualquier computadora tiene algún tipo de instrucción
que pueda realizar la función de un semáforo. Algunas
versiones permiten posicionar x mediante un código que identifica
al propietario actual; otras versiones pueden contar con él
numero de solicitudes que se están deteniendo. |
|||||
Siempre
es posible implantar un campo identificador o de cuenta de
datos
al proteger un campo mismo de datos con un semáforo. |
|||||
El
empleo de seguros se logra obligando a que todas la transacciones
que deseen
al acceso s un objeto protegido verifiquen la posición del
semáforo. Comúnmente el sistema apoya esta verificación
durante la ejecución de las solicitudes de actualización.
Cuando es habla acerca de seguros posiblemente se trate de algún
medio para limitar y retrasar el acceso, comúnmente implantado
por el sistema a través de uno o varios semáforos. |
|||||
| Objetos que deben asegurarse | |||||
Un
sistema de base de datos orientado a los esquemas es capaz
de determinar
que campos de datos pueden ser alterados mediante una transacción
de actualización y puede asegurar solo en sus campos. Sin
embargo, ya que una operación REWRITE especifica todo un
registro, y ya que los sistemas de archivo general escribirán
el bloque completo a partir de los buffers de archivo, es difícil
utilizar este conocimiento detallado. |
|||||
| Granularidad | |||||
A
la elección del tamaño de los objetos que se
van a asegura se le denomina granularidad del seguro. La menor
unidad que puede
asegurarse mediante un esquema es un campo o un segmento. Para
acceso de archivo es un registro y la menor unidad para manejo
por buffer
es un bloque. |
|||||
Tener
pequeños gránulos aumentara considerablemente el desempeño
del sistema ya que la posibilidad de interferencia será menor.
Para las operaciones de lectura es posible manejar pequeños
gránulos; para actualización, posiblemente él
limite lo constituyan los bloques. Cuando se emplean gránulos
pequeños se debe tener mas seguros, por lo que serán
más difíciles de manejar. |
|||||
| Identificación de los objetos | |||||
La
identificación
de los gránulos, por ejemplo registros, es una función
de algún sistema supervisor. Cada granulo deberá estar
identificado en forma positiva. Posiblemente los usuarios no sean
capaces de reconocer nombres sinónimos de registro y sabrán
menos aun acerca de cualquier bloque compartido. |
|||||
Si
el seguro se aplica a todos los bloques, él numero relativo
de bloque proporciona la identificación necesaria. Para identificar
campos es posible utilizar una concatenación numero_bloque.numero_registro.numero_campo.
Él numero de registro en un bloque marcado se determina mediante
el esquema marcado y él numero de campo puede estar basado
en la anotación del esquema. Cuando un registro comprende
varios bloques, será necesario manejar los bloques múltiples
como si fueran un solo objeto. |
|||||
| TIPO DE SEGUROS | |||||
Intervalo
de Seguro.- El
empleo de seguros tiene una dimensión temporal. Un enfoque
de protección consiste en asegurar cada objeto leído,
o necesario para actualización posterior tanto como sea posible;
cuando la transacción se concluye, todos los seguros se liberarán. |
|||||
El
intervalo de seguros puede acortarse liberando los seguros
de un objeto en
cuanto se realice la actualización. Esto significa que cada
objeto que vaya a leerse tendrá que liberarse si se considera
una actualización. Cuando se utiliza el sistema es común
asegurar durante el intervalo READ_TO_UPDATE_REWRITE. |
|||||
Seguro
Diferido.- La
ampliación del concepto de transacción de dos fases
al empleo de seguros puede evitar asegurar recursos hasta que la
transacción esté totalmente definida. No asegurar
la transacción de inmediato significa que existe una posibilidad
de que otra transacción haya codificado los datos de manera
que sea necesario volver a leer todos los datos que contribuyan
al resultado. Cuando la transacción este lista para compromiso
todos los datos se vuelve a leer los datos con seguros. El tiempo
que los otros usuarios se ven excluidos se reduce, pero con un
costo:
es necesario leer dos veces cada registro. |
|||||
Asegurar
los dispositivos para reducir el intervalo de seguros.- El
costo
de una READ_TO_UPDATE extra, inmediatamente antes de REWRITE,
es pequeño ya que se espera poca interferencia de la localización.
Aunque se realice un READ el intervalo de seguro puede ser mucho
menor si no hay otras transacciones que realicen acceso a los dispositivos
que estén empleando y si se evitan las localizaciones. |
|||||
La
posibilidad de una localización entre READ_TO_UPDATE y REWRITE puede
evitarse permitiendo que el seguro que se posiciona en el momento
de la operación READ_TO_UPDATE, no solo excluye otros accesos
al objeto si no que excluya también todos los otros accesos
al dispositivo en su totalidad. En la tecnología de programación
se dice que la secuencia de instrucciones entre READ_TO_UPDATE y
la conclusión del REWRITE se vuelve una sección
critica. |
|||||
Especificación
de seguro.- Es
necesario que exista una forma de avisar al sistema de apoyo
a la base de datos que se ha solicitado el seguro de un objeto.
Seria de esperarse que el usuario final, El vendedor o el
oficinista,
solicitara la acción de aseguramiento. Comúnmente
la solicitud de seguro la realiza un programador de aplicaciones
que define a la transacción, el sistema de manejo de transacciones
o el sistema de archivo, en respuesta a las operaciones solicitadas |
|||||
Cuando
se reclama un objeto el sistema nota la intención de usarlo.
La reclamación. La reclamación es aceptable si no
puede provocar problemas. La observación se anota(de nuevo
utilizando un semáforo para evitar reclamaciones en conflicto)
y la transacción puede proceder. Si se niega la reclamación
la transacción tiene la posibilidad de continuar con otra
tarea, tal vez para volver después o quedar en una línea
de espera. |
|||||
Cuando
se logra el acceso a los objetos reclamado se colocan seguros.
Puede
haber retrasos, pero eventualmente una transacción que espere
en la línea correspondiente a un objeto obtendrá el
acceso al objeto reclamado y podrá proceder. La transacción
coloca un seguro para lograr así el acceso exclusivo al objeto,
y este seguro se conservara hasta que la transacción ejecute
un comando RELEASE. Las reclamaciones conservadas por una transacción
también se liberan cuando una transacción se concluye
o aborta |
|||||
Interacciones
entre seguros.- Se
mostró que es necesario proporcionar aseguramiento entre
transacciones de actualización y entre consultas sólo
de lectura que requieran resultados que puedan soportar una auditoria
y transacciones de actualización. Las consultas sólo
de lectura no interfieren unas con otros. El empleo de aseguramiento
vuelve inaccesibles a una parte de la base de datos. |
|||||
| El manejo por bloques se logra al tener un semáforo de aseguramiento posicionado en el objeto de las operaciones. | |||||
| PROTOCOLOS | |||||
| PROTOCOLO DE BLOQUEO DE DOS FASES | |||||
Protocolo
que asegura la secuencialidad es el protocolo de bloqueo de
dos
fases. Este protocolo exige que cada transacción realice
las peticiones de bloqueo y desbloqueo de dos fases. |
|||||
| 1.- Fase de crecimiento.- Una transacción puede obtener bloqueos pero no puede liberarlos. | |||||
| 2.- Fase de decrecimiento.- Una transacción puede liberar bloqueos pero no puede obtener ninguno nuevo | |||||
Inicialmente
una transacción está en la fase de crecimiento. La
transacción adquiere los bloqueos que necesite. Una vez que
la transacción entra un bloqueo, entra en la fase de crecimiento
como puede alcanzar peticiones de bloqueo. |
|||||
Se
puede mostrar que el protocolo de bloqueo de dos fases asegura
secuencialidad
en cuanto a conflictos. Considérese cualquier transacción.
El punto de la planificación en el cual la transacción
obtiene el bloqueo final (el final de la fase de crecimiento) se
denomina punto de bloqueo de la transacción. El protocolo de bloqueo de dos fase no asegura la ausencia de interbloqueos. |
|||||
Los
retrocesos en cascada se pueden evitar por medio de una modificación
del protocolo de dos fases que se denomina protocolo de bloque
estricto
de dos fases. |
|||||
El
protocolo de bloque estricto de dos fases exige que además de que el
bloqueo sea de dos fases, una transacción debe poseer todos
los bloqueos en modo exclusivo que tome hasta que dicha transacción
no comprometida está bloqueado en modo exclusivo hasta que
la transacción lea el dato.. |
|||||
Otra
variante del bloqueo de dos fases es el protocolo de bloqueo
riguroso
de dos fases, el cual exige que se posean todos los bloqueos
hasta que se comprometan la transacción. Se puede comprobar fácilmente
que con el bloqueo riguroso de dos fases se pueden secuenciar
las
transacciones en el orden en que se comprometen. |
|||||
| Muchos sistemas de base de datos implementan tanto el bloqueo estricto como el bloqueo estricto de dos fases. | |||||
| PROTOCOLOS BASADOS EN GRAFOS. | |||||
En
ausencia de información acerca de la forma en que se accede a los
elementos de datos, el protocolo de bloqueo de dos fases es necesario
y suficiente para asegurar la secuencialidad. Así, si se
desea desarrollar protocolos que no sean de dos fases, es necesario
tener información adicional acerca de la forma en que cada
transacción accede a la base de datos. |
|||||
Existen
varios modelos que diferensea en la cantidad de información
que se proporciona. El modelo más simple que tenga conocimiento
previo acerca con el cual accede a los elementos de la base de
datos. |
|||||
Dada
la información es posible construir protocolos de bloqueos
que no sean de dos fases pero que un obstante persigue la secuencialidad
para adquirir al conocimiento previo que impone orden para
el conjunto
D={d1,.......,dn}. |
|||||
El
orden parcial implica que el conjunto D se puede ver como un
grafo aciclico
dirigido grafo de la base de datos. En este apartado, para simplificar,
se centra la atención solo en aquellos grafos que sean árboles
con raíz. Se puede presentar un protocolo simple llamado
protocolo de árbol, el cual esta restringido a utilizar
solo bloqueos de archivos. |
|||||
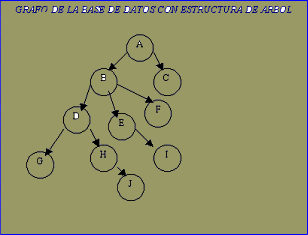
| Para ilustrar este protocolo, considérese el grafo de la base de datos de la Fig. 14.6. | |||||
Las
4 transacciones siguientes siguen el protocolo de árbol
sobre dicho grafo. Solo de muestran las instrucciones de bloqueo
y desbloqueo: |
|||||
| T10: bloquear-X(B) ;bloquear-X(E); bloquear-X(D); desbloquear(B) ; desbloquear (E); bloquear-X(G); desbloquear (D); desbloquear (G). | |||||
| T11: bloquear-X(D) ;bloquear-X(H); desbloquear(D) ; desbloquear (H). | |||||
| T12: bloquear-X(B) ;bloquear-X(E); desbloquear (E); desbloquear (B). | |||||
T13:
bloquear-X(D); bloquear-X(H); desbloquear (D); desbloquear (H).
|
|||||
| PROTOCOLOS BASADOS EN MARCAS TEMPORALES | |||||
Otro
método para determinar el orden de secuencialidad es seleccionarpreviamente
un orden entre las transacciones en el método más
común parahacer esto es utilizar un esquema de ordenación
por marcas temporales |
|||||
| MARCAS TEMPORALES | |||||
A
toda transacción T1 del sistema se le asocia una única
marca temporal fijada, denotada por MT(Ti). El sistema base de datos
asigna una marca temporal antes de que comience la ejecución
de Ti. Si a la transacción Ti se le ha asignado la marca
temporal MT(Ti) y una segunda transacción Tj entra al sistema,
entonces MT(Ti)< MT(Tj). |
|||||
Las
marcas temporales de las transacciones determinan el orden
de secuencia.
De este modo, si MT(Ti)< MT(Tj), entonces el sistema deberá
asegurar que toda planificación que produzca es equivalente
a una planificación secuencial en la cual la transacción
Ti aparece antes que la transacción Tj. |
|||||
| PROTOCOLO DE ORDENACIÓN POR MARCAS TEMPORALES | |||||
El
protocolo de ordenación por marcas temporales asegura
que todas las operaciones leer y escribir conflictivas se ejecutan
en el orden
de las marcas temporales. |
|||||
El
protocolo de ordenación por marcas temporales asegura la secuencialidad
en cuanto conflictos. Esta afirmación se deduce del hecho
de que las operaciones conflictivas se procesan durante la ordenación
de las marcas temporales. El protocolo asegura la ausencia de interbloqueos,
ya que ninguna transacción tiene que esperar. El protocolo
puede generar planificaciones no recuperables; sin embargo se
puede
extender para producir planificaciones sin cascada. |
|||||
| PROTOCOLOS BASADOS EN VALIDACION. | |||||
Para
aquellos casos en los que la mayoría de las transacciones
son de solo lectura. La tasa de conflictos entre las transacciones
puede ser baja. |
|||||
Así
muchas de esas transacciones, si se ejecutasen sin la supervisión
en un sistema de control de concurrencia, llevarían no
obstante al sistema a un estado consistente. |
|||||
Un
esquema de control de concurrencia supone una sobrecarga en
la ejecución
del código y un posible retardo en las transacciones. La
dificultad de reducir la sobrecarga está en que no se conoce
de antema las transacciones que estarán involucradas en
unos conflictos. Para obtener dicho conocimiento se necesita
un esquema
para observar el sistema. |
|||||
Se
asume que cada transacción Ti se ejecuta en dos o tres fases diferentes
durante su tiempo de vida, dependiendo de sí es una transacción
de solo lectura o una actualización. Las fases son en
orden que sigue:
|
|||||
| DEAD LOCK (BLOQUEO) | |||||
| Existen varios modos de bloquear un dato. | |||||
Compartido.- si
una transacción ha obtenido un bloqueo de modo compartido
en el dato, entonces puede leer este dato, pero no puede escribir. |
|||||
| Exclusivo.- si una transacción ha obtenido en bloqueo de modo exclusivo en el dato, entonces puede leer y escribir. | |||||
Exigimos
que todas las transacciones pidan un bloqueo en el modo adecuado
en el dato dependiendo del tipo de operaciones que van a realizar.
|
|||||
Dado
un conjunto de modos de bloqueo, podemos definir una función
de compatibilidad en ellos de la siguiente manera, sean modos de
bloqueo arbitrarios. Supóngase que una transacción
tiene actualmente un bloqueo, inmediatamente, a pesar de la presencia
del bloqueo de modo, entonces decimos que el modo es compatible
con el modo, este tipo de funciones puede representarse de forma
conveniente por medio de una matriz. La relación de compatibilidad
entre los dos nodos de bloqueo que se utilizan en esta sección. |
|||||
Una
transacción solicita un bloqueo compartido en el dato q ejecutando
la instrucción lock-s (Q. De manera similar, un bloqueo exclusivo
se solicita por medio de la instrucción lock-x (Q. Un dato
(Q) puede desbloquearse por medio de la instrucción unlock
(Q. |
|||||
Para
acceder a un dato la transacción primero debe bloquearlo,
el dato ya esta bloqueado por otra transacción en un modo
incompatible, debe esperar hasta que se liberen todos los bloqueos
incompatibles que tengan otras transacciones. |
|||||
Cabe
hacer notar que una transacción debe tener un bloqueo en
un dato mientras este accediendo a el. Además, no siempre
es deseable que una transacción desbloquee un dato inmediatamente
después de su ultimo acceso a ese dato, ya que existe
la posibilidad de que no pueda. |
|||||
| Causas de Punto Muerto. | |||||
Los
puntos muertos ocurren cuando dos o más transacciones solicitan
recursos en forma incremental y se bloquean mutuamente impidiéndose
una a otra la conclusión. Las transacciones y recursos
forman un ciclo. |
|||||
Hasta
es posible que un punto muerto se cree cuando se realiza al
acceso
a un solo objeto mediante dos transacciones y se aceptan reclamaciones
increméntales. |
|||||
Este
tipo de punto muerto tiene una mayor probabilidad de ocurrir
si
los objetos que se están asegurando son grandes cuando la
unidad de aseguramiento es un archivo la primera reclamación
puede emitirse para lograr acceso a un registro y la reclamación
incremental emitirse a fin de actualizar otro registro de archivo. |
|||||
Puntos
muertos debidos a recursos compartidos del sistema, los puntos
muertos
también pueden provocarse debido a la competencia por objetos
que no estén identificados en forma especifica, pero que
sean miembros de una clase compartida de recursos. Un bloqueo
temporal
ocurre cuando los limites de un recurso se alcanzan. |
|||||
Las
transacciones que se comunican a fin de procesar conjuntamente
datos
de proceso también están sujetas a puntos muertos,
un ejemplo de transacción en cooperación de este tipo
ocurre cuando los datos son trasladados entre archivos y buffers
por una transacción y procesados simultáneamente por
otras. Una transacción puede generar datos que se escriban
en los archivos con una gran velocidad y apoderarse de todos los
buffers. Ahora una transacción de análisis de datos
no puede proceder debido a que la transacción que los trasladando
puede entregar datos adicionales debido a escasez de buffers ya
que la transacción de análisis de los datos no libera
sus buffers hasta que concluya, de nuevo, se presenta una situación
clásica de punto muerto, los mecanismos para manejar los
puntos muertos deben, incluir, todos los objetos asegurables, esto
podría incluir unidades de cinta, impresora y otros dispositivos,
buffers y áreas de memoria asignados por el sistema operativo,
archivos de bloques y registros controlados por el sistema de
archivos
y de la base de datos. |
|||||
Condiciones
de punto muerto, la posibilidad de puntos muertos existen cuatro
condiciones [coffman]:
|
|||||
| Técnicas para prevenirlo | |||||
| Como evitar los puntos muertos. | |||||
Para
evitar puntos muertos puede simplificar muchas de elecciones
alternativas.
Los esquemas para evitar estos casos imponen a los usuarios restricciones
que pueden resultar difíciles de aceptar. Existen 4
enfoques para puntos muertos.
|
|||||
| Reparación posterior: | |||||
El
primer enfoque, es reparar posteriormente los problemas debido
a
no asegurar, puede responder a un valido en sistemas experimentales
y educativos, pero resulta inaceptable en la mayoría de las
aplicaciones comerciales. Si los sistemas tienen ya algunos medios
para reparar el daño debido a errores, el enfoque puede
resultar tolerable. |
|||||
| No bloquear: | |||||
El
segundo enfoque asigna la responsabilidad a la transacción,
el sistema proporcionara un aviso de interferencia potencial
al negar la solicitud
de acceso explosivo. |
|||||
La
transacción
puede proceder, arriesgándose a que los datos sean modificados
o puede esperar para volver a iniciar después, si la transacción
desea estar segura, entonces reclamara previamente todos los recursos
necesarios antes de realizar el acceso a ellos. Ya que este enfoque
también evita la circularidad, se analizara mas adelante
si la transacción continua, tal vez simplemente avise
a quien la presento que se ha detectado la existencia de interferencia. |
|||||
| Asignación previa: | |||||
La
asignación
previa de reclamaciones otorgados a las transacciones reuniere de
una capacidad de "volver a enrollar" .La transacción,
cuando se le notifica que no puede continuar, tiene que restaurar
la base de datos y colocarse así misma en la línea
de espera para un nuevo turno o el sistema tiene que eliminar la
transacción, restaurar la base de datos y volver a iniciar
de nuevo la transacción. |
|||||
| Secuencia previa: | |||||
Consiste
en evitar la circularidad en la secuencia de solicitud, en
este
caso existen tres enfoques, vigilancia de la existencia para
evitar la circularidad y aseguramiento de dos fases, a fin
de evitar puntos
muertos puede vigilarse el patrón de solicitud para todas
las transacciones. Si se detectan condiciones de circularidad potencial
que podrían provocar un fenómeno de este tipo pueden
bloquearse las transacciones candidato. |
|||||
| Aseguramiento de dos fases: | |||||
Un
enfoque simple para evitar la circularidad consiste en hacer
que se reclamen
previo todos los objetos antes de otorgar ningún seguro,
el reclamar los recursos antes de prometer otorgar el acceso a ellos
significa que posiblemente una transacción no sea capaz a
ellos significa que posiblemente una transacción no sea capaz
de concluir la fase de reclamación previa. Una vez que se
han hecho todas las reclamaciones es posible colocar seguros para
proteger a esta transacción, a esta técnica sé
él denomina aseguramiento de dos fases y funciona bien en
un medio que utilice un protocolo de compromiso de dos fases para
las transacciones. |
|||||
El
problema de dos fases es que la reclamación previa puede llegar a
tener que reclamar mas y mayores objetos de los que en realidad
se necesita, si un calculo sobre los datos determina que objetos
se necesitan después, es posible que se reclame en forma
previa todo un archivo en vez de un registro. |
|||||
| Recursos reservados: | |||||
Los
puntos muertos provocados por la competencia de recursos clasificados
(unidades de cinta, unidades de disco, memoria) algunas veces
se
disminuye al no permitir que ninguna nueva transacción se
inicie cuando la utilización llega a cierto nivel. Esta técnica
no asegura evitar los puntos muertos a menos que la reserva se conserve
de un tamaño tan granse que resulte poco practico, lo
suficiente para permitir que todas las transacciones activas
se concluyan. |
|||||
| Detención de puntos muertos | |||||
La
detección
de puntos muertos se realiza demasiado tarde, el único remedio
cuando se detecta en punto muerto consiste en eliminar una transacción
de la mejor forma posible. Sin embargo la detección de
puntos muertos es una tarea importante en el mantenimiento de
integridad
del sistema. |
|||||
Si
evitar puntos muertos es ya parte del sistema, entonces la
detección
de ellos proporciona un punto de interrupción que permite
la corrección de fallas en programas o hardware. En un medio
ambiente en que la responsabilidad de detección de muertos
corresponde a los programadores, disponer de la posibilidad de detección
de ellos es vital. |
|||||
La
detección
de puntos muertos mediante análisis lógicos es imposible
si el objeto no pueden identificarse. Una transacción
que espera una solicitud previamente a cualquiera de cierto numero
de
terminales. |
|||||
| Técnicas | |||||
El
esfuerzo para evitar o detectar los puntos muertos pueden ser
importantes,
el tiempo se ve afectado por él numero de transacciones y
él número de objetos que se aseguran, si ambos son
pequeños, una matriz transacciones objeto puede describir
el patrón de aseguramiento, los elementos de la matriz necesitan
solo uno o dos bits. Para reclamaciones referentes a clase de recursos,
se requieren enteros para detectar él numero reclamado
y recibido. |
|||||
Si
la probabilidad de puntos muerto es baja, puede resultar factible
efectuar
pruebas referentes a la existencia de puntos muertos solo en
forma periódica. Tal vez esto permita que el punto muerto
se disemine conforme otras transacciones intenten utilizar
las regiones bloqueadas. |
|||||
Los
sistemas orientados a transacciones tienden a minimizar la
interferencia
potencial conservando de transacciones activas. Se asigna una
alta prioridad a aquellas transacciones que retienen recursos,
de manera
que salgan del sistema tan rápido como sea posible. Para
la detención de puntos muertos resultan adecuados dos listas,
una para llevar un registro de los objetos y otra del estado de
cada transacción. Por cada transacción activa existe
una anotación en la lista de objetos ordenados léxicamente.
Si cuando se solicitan un objeto se encuentra que ya esta en la
lista y la transacción a que pertenece esta bloqueada,
existe cierta posibilidad de puntos muertos y se realiza la prueba
para
determinar si existe circularidad. |
|||||
| TÉCNICAS PARA DESHACERLO | |||||
| Evasión de Dead locks | |||||
Si
se tiene cuidado en la forma de asignar los recursos se pueden
evitar
situaciones de Dead lock. Supongamos un ambiente en el que todos
los procesos declaren a priori la cantidad máxima de recursos
que habrá de usar. |
|||||
Estado
seguro: un estado es seguro si se pueden asignar recursos a
cada
proceso (hasta su máximo) en algún orden sin que se
genere Dead lock. El estado es seguro si existe un ordenamiento
de un conjunto de procesos{P1...Pn} tal que para cada Pi los recursos
qi ePi podrá utilizar pueden ser otorgados por los recursos
disponibles mas los recursos utilizados por los procesos Pjj < i
Si los recursos solicitados por Pi no pueden ser otorgados, Pi
espera a que todos los procesos Pj hayan terminado. |
|||||
| Detección y Recuperación de Dead locks | |||||
(Algoritmos
de detección de Dead locks)
|
|||||
Recuperación
de Dead locks
|
|||||
| ETIQUETAS DE TIEMPO | |||||
Para
evitar interferencia debida a la concurrencia se usa el aseguramiento
o el tiempo de estampado para seriar la ejecución de transacciones
concurrentes, de cualquier modo, estas estrategias requieren de
complicados protocolos de control los que pueden deteriorar el desempeño
del sistema al generar trafico extra entre las distintas localidades. |
|||||
| Algoritmos Basados en estampas de tiempo | |||||
A
diferencia de los algoritmos basados en candados, los algoritmos
basados en
estampas de tiempo, no pretenden mantener la seriabilidad por
exclusión
mutua, en lugar de eso ellos seleccionan un orden de seriabilización
a priori y ejecutan las transacciones de acuerdo a ellas. |
|||||
Para
establecer este ordenamiento, el administrador de transacciones
le asigna a cada transacción T1 una estampa de tiempo única
Ts (Ti) cuando esta inicia. |
|||||
| Estampa de tiempo | |||||
Existen
varias formas en que las estampas de tiempo se pueden asignar,
un
método es usar un controlador global monotonicamente creciente,
es preferible que cada nodo asigne de manera autónoma las
estampas de tiempos basándose en un contador local, para
obtener la unicidad, cada nodo le agrega al contador su propio identificador,
así la estampa de tiempo es un par dela forma:
|
|||||
El
identificador de nodo se agrega en la posición menos
significativa, de manera que este sirve solo en el caso en
que dos nodos diferentes
le asignen el mismo contador local a dos transacciones diferentes. |
|||||
El
administrador de transacciones asigna también una estampa de tiempo a todas
las operaciones solicitadas por una transacción, a cada elemento
de datos x se le asigna una estampa de tiempo de escritura, wts(x),
y una estampa de tiempo de lectura, rts(x); sus valores indican
la estampa de tiempo más grande para cualquier lectura
y escritura de x, respectivamente. |
|||||
| El ordenamiento de estampas de tiempo (TO) se realiza mediante la siguiente regla: | |||||
Regla
TO: Dadas dos operaciones en conflicto, Oij y Okl, perteneciendo
a las transacciones Ti y Tk respectivamente , Oij es ejecutada
antes
de Okl, si y solamente si, ts(Ti) < ts(Tk), en este caso Ti se
dice ser una transacción mas vieja y Tk se dice ser una transacción
mas joven. |
|||||
La
acción
de rechazar una operación, significa que la transacción
que la envió necesita reiniciarse para obtener la estampa
de tiempo mas reciente del dato, e intentar nuevamente la operación
sobre el dato. |
|||||