Información: Es
un conjunto ordenado de datos los cuales son manejados según
la necesidad del usuario, para que un conjunto de datos pueda ser
procesado eficientemente y pueda dar lugar a información,
primero se debe guardar lógicamente en archivos.
Campo: Es
la unidad más pequeña a la cual uno puede referirse
en un programa. Desde el punto de vista del programador representa
una característica de un individuo u objeto.
Base
de datos: Es
una colección de archivos interrelacionados, son creados
con un DBMS. El contenido de una base de datos engloba a la información
concerniente(almacenadas en archivos) de una organización,
de tal manera que los datos estén disponibles para los usuarios,
una finalidad de la base de datos es eliminar la redundancia o al
menos minimizarla. Los tres componentes principales de un sistema
de base de datos son el hardware, el software DBMS y los datos a
manejar, así como el personal encargado del manejo del
sistema.
Una colección de datos interrelacionados que se puede utilizar por uno o más programas de aplicación.
Una colección de datos interrelacionados que se puede utilizar por uno o más programas de aplicación.
Un
DBMS es una colección de numerosas rutinas de software interrelacionadas,
cada una de las cuales es responsable de una tarea específica.
Un
DBMS consiste de una base de datos y un conjunto de aplicaciones
(programas) para tener acceso a ellos. Comúnmente, la base
de datos contiene información interrelacionada y referente
a una misma entidad o empresa.
El
objetivo primordial de un sistema manejador base de datos es
proporcionar
un contorno que sea a la vez conveniente y eficiente para ser
utilizado al extraer, almacenar y manipular información
de la base de datos. Todas las peticiones de acceso a la base,
se manejan centralizadamente
por medio del DBMS, por lo que este paquete funciona como interfase
entre los usuarios y la base de datos.
En
resumen el objetivo primordial de una DBMS es crear un ambiente
en el que
sea posible almacenar y recuperar información en forma
eficiente y conveniente.
Otro
modelo que se utiliza comúnmente para manipular una base
de datos es el llamado SISTEMA DE PROCESAMIENTO DE ARCHIVOS; que
consta de un conjunto de programas que permiten el acceso a la base
de datos, pero no optimizan los métodos utilizados, provocando
entre otros los siguientes problemas:
REDUNDANCIA.- Esta
se presenta cuando se repiten innecesariamente datos en los
archivos que conforman la base de datos.
Esta redundancia aumenta los costes de almacenamiento y acceso y además puede llevar a inconsistencia de los datos.
Esta redundancia aumenta los costes de almacenamiento y acceso y además puede llevar a inconsistencia de los datos.
INCONSISTENCIA.-
Ocurre
cuando existe información contradictoria o incongruente
en la base de datos.
DIFICULTAD
EN EL ACCESO A LOS DATOS.- Debido
a que los sistemas de procesamiento de archivos generalmente
se
conforman en distintos tiempos o épocas y ocasionalmente
por distintos programadores, el formato de la información
no es uniforme y se requiere de establecer métodos de enlace
y conversión para combinar datos contenidos en distintos
archivos.
AISLAMIENTO
DE LOS DATOS.- Se
refieren a la dificultad de extender las aplicaciones que permitan
controlar a la base de datos, como pueden ser, nuevos reportes,
utilerías y demás debido a la diferencia de formatos
en los archivos almacenados.
ANOMALIAS
EN EL ACCESO CONCURRENTE.- Ocurre
cuando el sistema es multiusuario y no se establecen los controles
adecuados para sincronizar los procesos que afectan a
la base de datos. Comúnmente se refiere a la poca o nula
efectividad de los procedimientos de bloqueo.
PROBLEMAS
DE SEGURIDAD.- Se
presentan cuando no es posible establecer claves de acceso y
resguardo en forma uniforme para todo el sistema, facilitando
así el acceso a intrusos.
PROBLEMAS
DE INTEGRIDAD.- Ocurre
cuan no existe a través de todo el sistema procedimientos
uniformes de validación para los datos.
Es
una interface entre los datos de bajo nivel y los programas
de aplicación
y módulos de consulta que se utilizan a nivel de usuario.
El
sistema manejador de bases de datos es la porción más
importante del software de un sistema de base de datos. Un DBMS
es una colección de numerosas rutinas de software interrelacionadas,
cada una de las cuales es responsable de alguna tarea específica.
- Crear y organizar la Base de datos.
-
Establecer y mantener las trayectorias de acceso a la base de datos de tal forma que los datos puedan ser accesados rápidamente.
- Manejar los datos de acuerdo a las peticiones de los usuarios.
- Registrar el uso de las bases de datos.
-
Interacción con el manejador de archivos. Esto a través de las sentencias en DML al comando de el sistema de archivos. Así el Manejador de base de datos es el responsable del verdadero almacenamiento de los datos.
-
Respaldo y recuperación. Consiste en contar con mecanismos implantados que permitan la recuperación fácilmente de los datos en caso de ocurrir fallas en el sistema de base de datos.
-
Control de concurrencia. Consiste en controlar la interacción entre los usuarios concurrentes para no afectar la inconsistencia de los datos.
- Seguridad e integridad. Consiste en contar con mecanismos que permitan el control de la consistencia de los datos evitando que estos se vean perjudicados por cambios no autorizados o previstos.
-
Implantación de integridad, se encarga de verificar que durante las actualizaciones no se viole ninguna limitante de consistencia.
-
Mejoramiento del nivel de seguridad, se encarga de restringir el acceso mediante una serie de password u otros medios de identificación y validación.
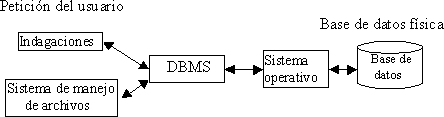 |
La
figura muestra el DBMS como interfase entre la base de datos
física
y las peticiones del usuario. El DBMS interpreta las peticiones
de entrada/salida del usuario y las manda al sistema operativo
para
la transferencia de datos entre la unidad de memoria secundaria
y la memoria principal.
En
sí,
un sistema manejador de base de datos es el corazón de
la base de datos ya que se encarga del control total de los posibles
aspectos que la puedan afectar.
Esquema
de base de datos: Es
la estructura por la que esta formada la base de datos, se especifica
por medio de un conjunto de definiciones que se expresa mediante
un lenguaje especial llamado lenguaje de definición de
datos. (DDL)
Administrador
de base de datos (DBA): Es
la persona o equipo de personas profesionales responsables del
control
y manejo del sistema de base de datos, generalmente tiene(n)
experiencia en DBMS, diseño de bases de datos, Sistemas operativos, comunicación
de datos, hardware y programación.
Definición
de esquema:
Es el esquema original de la base de datos se crea escribiendo un
conjunto de definiciones que son traducidas por el compilador de
DDL a un conjunto de tablas que son almacenadas permanentemente
en el diccionario de datos.
Definición
de la estructura de almacenamiento del método de acceso: Estructuras
de almacenamiento y de acceso adecuados se crean escribiendo
un conjunto de definiciones que son traducidas por e compilador
del lenguaje de almacenamiento y definición de datos.
Concesión
de autorización para el acceso a los datos: Permite
al administrador de la base de datos regular las partes de las bases
de datos que van a ser accedidas por varios usuarios.
Especificación
de límitantes de integridad: Es
una serie de restricciones que se encuentran almacenados en una
estructura especial del sistema que es consultada por el gestor
de base de datos cada vez que se realice una actualización
al sistema.
El
DBA es quien tiene el control centralizado de la base de datos.
Se persigue
con esto reducir el número de personas que tengan acceso
a los detalles técnicos y de diseño para la operación
del DBMS.
Los
sistemas de base de datos se diseñan para manejar grandes
cantidades de información, la manipulación de los
datos involucra tanto la definición de estructuras para el
almacenamiento de la información como la provisión
de mecanismos para la manipulación de la información,
además un sistema de base de datos debe de tener implementados
mecanismos de seguridad que garanticen la integridad de la información,
a pesar de caídas del sistema o intentos de accesos no
autorizados.
Un
objetivo principal de un sistema de base de datos es proporcionar
a los usuarios finales una visión abstracta de los datos,
esto se logra escondiendo ciertos detalles de como se almacenan
y mantienen los datos.
-
Redundancia e inconsistencia de datos.
Puesto que los archivos que mantienen almacenada la información son creados por diferentes tipos de programas de aplicación existe la posibilidad de que si no se controla detalladamente el almacenamiento, se pueda originar un duplicado de información, es decir que la misma información sea más de una vez en un dispositivo de almacenamiento. Esto aumenta los costos de almacenamiento y acceso a los datos, además de que puede originar la inconsistencia de los datos - es decir diversas copias de un mismo dato no concuerdan entre si -, por ejemplo: que se actualiza la dirección de un cliente en un archivo y que en otros archivos permanezca la anterior. -
Dificultad para tener acceso a los datos.
Un sistema de base de datos debe contemplar un entorno de datos que le facilite al usuario el manejo de los mismos. Supóngase un banco, y que uno de los gerentes necesita averiguar los nombres de todos los clientes que viven dentro del código postal 78733 de la ciudad. El gerente pide al departamento de procesamiento de datos que genere la lista correspondiente. Puesto que esta situación no fue prevista en el diseño del sistema, no existe ninguna aplicación de consulta que permita este tipo de solicitud, esto ocasiona una deficiencia del sistema. -
Aislamiento de los datos.
Puesto que los datos están repartidos en varios archivos, y estos no pueden tener diferentes formatos, es difícil escribir nuevos programas de aplicación para obtener los datos apropiados. -
Anomalías del acceso concurrente.
Para mejorar el funcionamiento global del sistema y obtener un tiempo de respuesta más rápido, muchos sistemas permiten que múltiples usuarios actualicen los datos simultáneamente. En un entorno así la interacción de actualizaciones concurrentes puede dar por resultado datos inconsistentes. Para prevenir esta posibilidad debe mantenerse alguna forma de supervisión en el sistema. -
Problemas de seguridad.
La información de toda empresa es importante, aunque unos datos lo son más que otros, por tal motivo se debe considerar el control de acceso a los mismos, no todos los usuarios pueden visualizar alguna información, por tal motivo para que un sistema de base de datos sea confiable debe mantener un grado de seguridad que garantice la autentificación y protección de los datos. En un banco por ejemplo, el personal de nóminas sólo necesita ver la parte de la base de datos que tiene información acerca de los distintos empleados del banco y no a otro tipo de información. -
Problemas de integridad.
Los valores de datos almacenados en la base de datos deben satisfacer cierto tipo de restricciones de consistencia. Estas restricciones se hacen cumplir en el sistema añadiendo códigos apropiados en los diversos programas de aplicación.
Un
sistema de gestión de base de datos (DBMS) consiste en una colección
de datos interrelacionados y un conjunto de programas para acceder
a esos datos. La colección de datos, normalmente denominada
base de datos, contiene información acerca de una empresa
determinada. El objetivo primordial de un DBMS es proporcionar un
entorno que sea a la vez conveniente y eficiente para ser utilizado
al extraer y almacenar información de la base de datos.
Los sistemas de bases de datos están diseñados para gestionar grandes bloques de información. La gestión de datos implica tanto la definición de estructuras para el almacenamiento de información como la provisión de mecanismos para la gestión de la información. Además, los sistemas de bases de datos deben mantener la seguridad de la información almacenada, pese a caídas del sistema o intentos de accesos no autorizados. Si los datos van a ser compartidos por varios usuarios, el sistema debe evitar posibles resultados anómalos.
La importancia de la información en la mayoría de las organizaciones, y por tanto el valor de la base de datos, ha llevado al desarrollo de una gran cantidad de conceptos y técnicas para la gestión eficiente de los datos. En este capitulo presentamos una breve introducción a los principios de los sistemas de bases de datos.
Los sistemas de bases de datos están diseñados para gestionar grandes bloques de información. La gestión de datos implica tanto la definición de estructuras para el almacenamiento de información como la provisión de mecanismos para la gestión de la información. Además, los sistemas de bases de datos deben mantener la seguridad de la información almacenada, pese a caídas del sistema o intentos de accesos no autorizados. Si los datos van a ser compartidos por varios usuarios, el sistema debe evitar posibles resultados anómalos.
La importancia de la información en la mayoría de las organizaciones, y por tanto el valor de la base de datos, ha llevado al desarrollo de una gran cantidad de conceptos y técnicas para la gestión eficiente de los datos. En este capitulo presentamos una breve introducción a los principios de los sistemas de bases de datos.
Un
sistema de base de datos se encuentra dividido en módulos cada uno
de los cuales controla una parte de la responsabilidad total de
sistema. En la mayoría de los casos, el sistema operativo
proporciona únicamente los servicios más básicos
y el sistema de la base de datos debe partir de esa base y controlar
además el manejo correcto de los datos. Así el diseño
de un sistema de base de datos debe incluir la interfaz entre
el
sistema de base de datos y el sistema operativo.
Gestor
de archivos. Gestiona
la asignación de espacio en la memoria del disco
y de las estructuras de datos usadas para representar información.
Procesador
de consultas. Traduce
las proposiciones en lenguajes de consulta a instrucciones de
bajo nivel. Además convierte la solicitud del usuario
en una forma más eficiente.
Compilador
de DDL. Convierte
las proposiciones DDL en un conjunto de tablas que contienen metadatos,
estas se almacenan en el diccionario de datos.
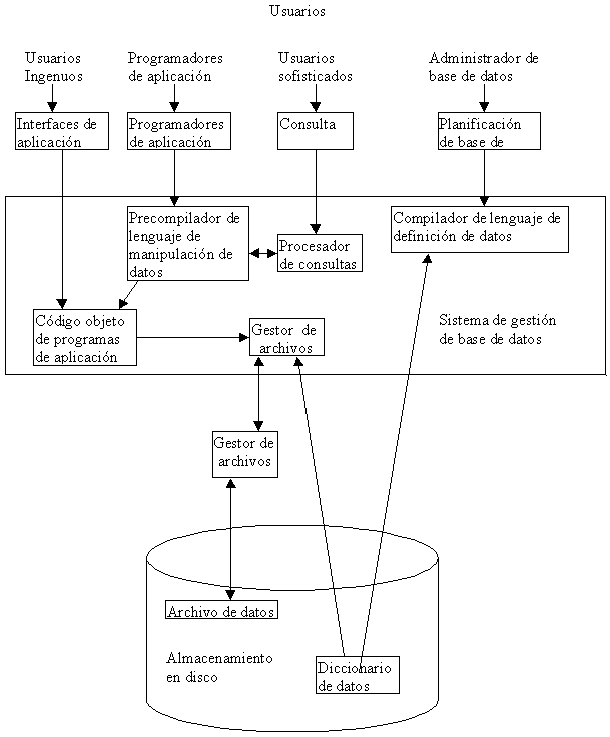 |
La
seguridad se refiere a la protección de los datos contra su revelación,
su alteración o su destrucción no autorizadas, mientras
que la integridad se refiere a la precisión o validez
de esos datos. La seguridad se refiere a proteger los datos ante
usuarios
no autorizados.
- Aspectos legales, sociales y éticos.
- Controles físicos
- Cuestiones de política
- Problemas operacionales
- Controles de hardware
- Soporte del sistema operativo
Actualmente
los Sistemas Administradores de Bases de Datos (DBMS) soportan generalmente
uno o ambos enfoques con respecto a la seguridad de los datos. Estos
enfoques son conocidos como Control Discrecional y Control Obligatorio.
En
el caso del Control Discrecional, un usuario especifico tendrá
generalmente diferentes derechos de acceso (conocidos como privilegios)
sobre diferentes objetos; además, existen muy pocas limitaciones
sobre que usuarios pueden tener que derechos sobre que objetos.
Por
el contrario, en el caso del Control Obligatorio, cada objeto
de
datos está etiquetado con un nivel de clasificación
determinado y a cada usuario se le da un nivel de acreditación.
Llamamos
autentificación a la comprobación de la identidad
de una persona o de un objeto. Hemos visto hasta ahora diversos
sistemas que pueden servir para la autentificación de servidores,
de mensajes y de remitentes y destinatarios de mensajes. Pero hemos
dejado pendiente un problema: las claves privadas suelen estar alojadas
en máquinas clientes y cualquiera que tenga acceso a estas
máquinas puede utilizar las claves que tenga instaladas y
suplantar la identidad de su legítimo usuario.
Por
tanto es necesario que los usuarios adopten medidas de seguridad
y utilicen los medios de autentificación de usuario de los
que disponen sus ordenadores personales. Hay tres sistemas de identificación
de usuario, mediante contraseña, mediante dispositivo y mediante
dispositivo biométrico.
La
autentificación mediante contraseña es el sistema
más común ya que viene incorporado en los sistemas
operativos modernos de todos los ordenadores. Los ordenadores que
estén preparados para la autentificación mediante
dispositivo sólo reconocerán al usuario mientras mantenga
introducida una "llave", normalmente una tarjeta con chip.
Hay sistemas de generación de claves asimétricas
que introducen la clave privada en el chip de una tarjeta inteligente.
Los
dispositivos biométricos son un caso especial del anterior,
en los que la "llave" es una parte del cuerpo del usuario,
huella dactilar, voz, pupila o iris. Existen ya en el mercado a
precios relativamente económicos ratones que llevan incorporado
un lector de huellas dactilares.
Ahora
bien ¿cómo se las arregla el sistema para llevar la
cuenta de quien puede acceder que objetos y con que operaciones?
Conceptualmente al menos, podemos ver este modelo de protección
como una gran matriz de acceso.
Los
cambios de dominio que un proceso puede hacer también podemos
integrarlos a la matriz, tratando a lo s dominios como otros objetos,
con una operación: entrar.
Una
política de protección involucra decidir como se va
a llenar esta matriz. Normalmente el usuario que crea un objeto
es quien decide como se va a llenar la columna de la matriz correspondiente
a ese objeto. La matriz de acceso es suficientemente general como
para apoyar diversas políticas. Por ejemplo:
El
problema es como almacenar esta matriz. Como es una matriz
poco densa (muchos
de los elementos son vacíos), no resulta practico representarla
como una matriz propiamente. Podríamos usar una tabla con
triples (dominio, objeto, derechos). Si un proceso dentro de un
dominio D intenta efectuar una operación M sobre un objeto
O, se busca (D,O,C), y se verifica si por ejemplo, leído
por todo el mundo, debe tener entradas para cada dominio.
Esquema
- El esquema de la base de datos, si existe, es otro objeto
que
debe someterse a protección. En este caso, hay que preocuparse
acerca de la asignación adecuada de objeto en un medio de
base de datos de esquema, cuando la protección se proporcione
a través del esquema mismo. Algunos sistemas pueden preservar
el esquema en un archivo controlado por esquema y aplicar protección
a través de esta recurrencia ascendente. Será necesario
proporcionar una conclusión adecuada a este nido de esquemas.
Si el esquema es relativamente estático, es posible incluir
el archivo de esquema en una sola descripción de esquema.
La asignación de privilegios de acceso al esquema es sumamente
importante. Muchos accesores tendrán privilegios de lectura
a los descriptores, pero muy pocos tendrán privilegios de
modificación o escritura. Un error al modificar un esquema
puede hacer que toda la base de datos quede inaccesible. Si el archivo
mismo de esquema esta controlado por el mismo esquema, resulta complicado
comprobar el uso de estos privilegios de modificación.
Una
protección mas fuerte del acceso al esquema podría
incluir el requerimiento de que más de un accesor asigne
un privilegio de acceso de modificación a un proceso que
cambie la tarea del esquema. Ambos recibirán informes de
todas las actividades. Esta autorización conjunta es equivalente
a la condición de doble firma que existe en muchas compañías
cuando se emiten cheques que amparen cantidades muy grandes. Un
método alterno de control consiste en mantener dos esquemas
que se regulen recíprocamente y a los que se les asignen
distintos accesores en el nivel superior, de manera que de nuevo
exista control conjunto.
Es
una forma lógica de ver los datos físicos ubicados
en tablas. Cuando creamos una vista, seleccionamos un formato que
incluye datos que pueden ser tomados de una o más tablas.
La vista queda almacenada en forma permanente, si bien los datos
grabados permanecen inalterados en las tablas correspondientes.
Una vista sólo es una ventana a los datos almacenados.
Utilizadas
como mecanismo de seguridad, las vistas restringen el acceso
de
un usuario a determinadas columnas de la tabla. Si la columna
excluida es la clave de la fila, también se está impidiendo
que el usuario pueda relacionar dos tablas.
En
la arquitectura de tres niveles estudiada se describe una vista
externa
como la estructura de la base de datos tal y como la ve un usuario
en particular. En el modelo relacional, el término `vista'
tiene un significado un tanto diferente. En lugar de ser todo el
esquema externo de un usuario, una vista es una relación
virtual, una relación que en realidad no existe como tal.
Una vista se puede construir realizando operaciones como las del
álgebra relacional: restricciones, proyecciones, concatenaciones,
etc.
Una
vista es el resultado dinámico de una o varias operaciones
relacionales realizadas sobre las relaciones base. Una vista es
una relación virtual que se produce cuando un usuario la
consulta. Al usuario le parece que la vista es una relación
que existe y la puede manipular como si se tratara de una relación
base, pero la vista no está almacenada físicamente.
El contenido de una vista está definido como una consulta
sobre una o varias relaciones base. Cualquier operación que
se realice sobre la vista se traduce automáticamente a operaciones
sobre las relaciones de las que se deriva. Las vistas son dinámicas
porque los cambios que se realizan sobre las tablas base que afectan
a una vista se reflejan inmediatamente sobre ella. Cuando un usuario
realiza un cambio sobre la vista (no todo tipo de cambios están
permitidos), este cambio se realiza sobre las relaciones de las
que se deriva.
-
Proporcionan un poderoso mecanismo de seguridad, ocultando partes de la base de datos a ciertos usuarios. El usuario no sabrá que existen aquellos atributos que se han omitido al definir una vista.
-
Permiten que los usuarios accedan a los datos en el formato que ellos desean o necesitan, de modo que los mismos datos pueden ser vistos con formatos distintos por distintos usuarios.
-
Se puede simplificar operaciones sobre las relaciones base que son complejas. Por ejemplo, se puede definir una vista como la concatenación de dos relaciones. El usuario puede hacer restricciones y proyecciones sobre la vista, que el SGBD traducirá en las operaciones equivalentes sobre la concatenación.
Se
puede utilizar una vista para ofrecer un esquema externo a
un usuario
de modo que éste lo encuentre `familiar'. Por ejemplo:
-
Un usuario puede necesitar los datos de los directores junto con los de las oficinas. Esta vista se crea haciendo una concatenación de las relaciones PLANTILLA y OFICINA, y proyectando sobre los atributos que se desee mantener.
-
Otro usuario puede que necesite ver los datos de los empleados sin ver el salario. Para este usuario se realiza una proyección para crear una vista sin el atributo salario.
-
Los atributos se pueden renombrar, de modo que cada usuario los vea del modo en que esté acostumbrado. También se puede cambiar el orden en que se visualizan las columnas.
-
Un miembro de la plantilla puede querer ver sólo los datos de aquellos inmuebles que tiene asignados. En este caso, se debe hacer una restricción para que sólo se vea el subconjunto horizontal deseado de la relación INMUEBLE.
Como
se ve, las vistas proporcionan independencia de datos a nivel
lógico,
que también se da cuando se reorganiza el nivel conceptual.
Si se añade un atributo a una relación, los usuarios
no se percatan de su existencia si sus vistas no lo incluyen. Si
una relación existente se reorganiza o se divide en varias
relaciones, se pueden crear vistas para que los usuarios la sigan
viendo como al principio.
Cuando
se actualiza una relación base, el cambio se refleja automáticamente
en todas las vistas que la referencian. Del mismo modo, si se actualiza
una vista, las relaciones base de las que se deriva deberían
reflejar el cambio. Sin embargo, hay algunas restricciones respecto
a los tipos de modificaciones que se pueden realizar sobre las vistas.
A continuación, se resumen las condiciones bajo las cuales
la mayoría de los sistemas determinan si se permite realizar
una actualización:
-
Se permiten las actualizaciones de vistas que se definen mediante una consulta simple sobre una sola relación base y que contienen la clave primaria de la relación base.
- No se permiten las actualizaciones de vistas que se definen sobre varias relaciones base.
- No se permiten las actualizaciones de vistas definidas con operaciones de agrupamiento ( GROUPBY)
Las
vistas es una forma de proporcionar al usuario un modelo "
personalizado " de la base de datos. Una vista puede ocultar
datos que el usuario no tiene necesidad de ver. El uso del sistema
es más sencillo porque el usuario puede restringir su atención
a los datos que le interesan. La seguridad se logra si se cuenta
con un mecanismo que limite a los usuarios a su vista o vistas
personales.
Lo normal es que las bases de datos relacionales cuenten con
los dos niveles de seguridad:
Aunque
es posible impedir que un usuario tanga acceso directo a una
relación,
puede permitirse acceso a una parte de esa relación por medio
de una vista. De tal manera, es posible utilizar una combinación
de seguridad al nivel relacional y al nivel de vistas para limitar
el acceso del usuario exclusivamente a los datos que necesita.
En
un banco considerar que un empleado que necesita saber los
nombres
de los clientes de cada una de las sucursales. El empleado no
cuenta con autorización para consultar información referente
a prestamos o cuentas especificas que pudiera tener el cliente.
Por tanto es preciso impedir que el empleado tenga acceso a las
relaciones préstamo y deposito. Para que el empleado pueda
obtener la información que necesita, se le concede acceso
a la vista todos-clientes, que consta solo de los nombres y las
sucursales a los que en los pertenecen. Definimos esta vista
utilizando
SQL de la siguiente manera:
union (select nombre-sucursal,nombre-cliente from prestamoIN)
La
criptografía
es una disciplina compleja en la que se halla involucrada una enorme
cantidad de matemática. En resumen, el objetivo de las técnicas
criptográficas es codificar mensajes de manera que cuando
estos tienen que transmitirse por medios de comunicación
no resistentes a intrusiones, sólo puedan ser interpretados
(desencriptados) por el interlocutor, que conocerá las técnicas
para deshacer la codificación llevada a cabo por el originador
del mensaje. El mensaje que se encripta, y que en adelante denominaremos
cifrado, no tiene porque contener texto ASCII exclusivamente, sino
que puede ser un archivo binario de bases de datos, o cualquier
otra información.
Cuando
se encripta un mensaje en las técnicas de encriptación
utilizadas en el ámbito de este artículo, se utiliza
una determinada llave criptográfica que debe ser conocida
por el destinatario del mensaje para proceder a su desencriptación.
De este modo, los mecanismos, esto es, los algoritmos de encriptación/desencriptación,
son del dominio público, con lo que cualquier desarrollador
o empresa puede generar programas que lleven a cabo las tareas
citadas
La
Criptografía
es la ciencia de escribir mensajes en clave secreta, pero también
existe su contraparte que es llamada Criptoanálisis el cual
es la ciencia de descifrar los mensajes creados por la Criptografía.
Al conjunto de estas dos ciencias se le conoce como Criptología.
La encriptación es básicamente transformar datos en
alguna forma que no sea legible sin el conocimiento de la clave
o algoritmo adecuado. El propósito de esta es mantener oculta
la información que consideramos privada a cualquier persona
o sistema que no tenga permitido verla. La encriptación en
general requiere el uso de información secreta para su funcionamiento
la cual es llamada "llave". Algunos sistemas de encriptación
utilizan la misma llave para codificar y descodificar los datos,
otros utilizan llaves diferentes.
La
técnica
de encriptación a aplicar se basa en la complejidad de la
información a ocultar, es decir, entre mas compleja sea la
información se debe aplicar un sistema de encriptación
mas robusto y viceversa.
Existen
dos tipos de técnicas de encriptación, la que utiliza
llave pública/llave privada y la llamada criptografía
simétrica la cual utiliza la misma llave para encriptar y
desencriptar la información. Entre los sistemas simétricos
de encriptación mas populares se encuentra el algoritmo llamado
DES el cual es usado por el gobierno de Estados Unidos como estándar
para sus comunicaciones, ya que el usuario final no conoce la llave.
Otro sistema de esta familia es el conocido como RC5. Una alternativa
a estos dos sistemas que son patentados es el algoritmo llamado
Solitaire el cual es de libre distribución y puede ser ocupado
sin ningún tipo de restricción
Existen
productos comerciales para implementar diversos algoritmos
de encriptación
como CryptoC de RSA Data Security el cual cuenta con la mayoría
de los algoritmos de encriptación de datos como RSA , DES,
SHA1, RC5 entre otros o el PGPsdk de Network Associates. El problema
aquí es el licenciamiento, el costo y la implantación
en cada aplicación del sistema.
La
mayoría
de algoritmos comerciales son propensos a sufrir ataques para descifrarlos
he incluso existen herramientas para este fin como el "40-bit
RC2 Cracking ScreenSaver" o los programas de distributed.net
para romper el RC5-64 o DES-III entre otros.
Dentro
del Criptoanálisis, existen diversos tipos de ataques a sistemas
criptográficos los cuales son aplicados dependiendo de la
situación en la que nos encontremos.
-
Ataque sólo con texto cifrado. Este tipo de ataque es el mas complicado de todos ya que únicamente se conoce el criptograma.
- Ataque con texto cifrado el cual contiene partes del texto original sin cifrar.
- Ataque con varios criptogramas conocidos del mismo texto original generados por distintas claves.
- Ataque con texto original conocido. Se tiene información del texto original del cual se generó el criptograma.
-
Ataque con texto original escogido. Se puede cifrar cualquier texto que queramos ver obteniendo el criptograma correspondiente, el cual es generado con el mismo cypher que el criptograma que se quiere descifrar.
-
Ataque con texto cifrado escogido. Este tipo de ataque se da cuando podemos obtener el texto original correspondiente a determinados criptogramas de nuestra elección.
Esto
es de una forma muy sencilla lo que es en general la Criptología,
dependiendo en que área nos adentremos, ya sea criptografía
o criptoanalisis existen muchos factores que intervienen en su desarrollo
he implementación.
Codificación
de datos con propósito de seguridad, convirtiendo el código
de datos estándar en un código propio. Los datos
cifrados deben codificarse para ser usados. El cifrado se usa
para transmitir
documentos por una red o para codificar el texto de modo tal
que no pueda ser modificado con un procesador de textos.
La
tecnología
de encriptación permite la transmisión segura de información
a través de internet, al codificar los datos transmitidos
usando una fórmula matemática que "desmenuza"
los datos. Sin el decodificador adecuado, la transmisión
luciría como un texto sin ningún sentido, el cual
resulta completamente inútil.
La
tecnología
de encriptación se usa para una variedad de aplicaciones,
tales como: comercio electrónico, envío de correo
electrónico y protección de documentos confidenciales.
La
encriptación
básica envuelve la transmisión de datos de una parte
a la otra. Quien envía la información la codifica
al "desmenuzarla" y enviarla de esta manera. El receptor
decodifica los datos con el decodificador adecuado, para poder así leerla
y usarla.
La
efectividad, o nivel de seguridad, de la encriptación se mide en términos
del tamaño de la clave (mientras más larga es la clave,
mayor sería el tiempo que le tomaría a una persona
sin el decodificador correcto para decodificar el mensaje). Esto
se mide en bits (por ejemplo, el nivel de encriptación utilizado
por los sistemas de banca en línea en el país es de
40-bits, mientras que el nivel de encriptación de Citibank
Online es de 128-bits). Para una clave de 40-bits existen 240 posibles
combinaciones distintas. Para una clave de 128-bits (el nivel de
encriptación utilizado en Citibank Online) existen 2128 posibles
combinaciones distintas. En opinión de Netscape, la encriptación
de 128-bits es 309.485.009.821.345.068.724.781.056 veces más
poderosa que la encriptación de 40-bits.
Entendemos
por Criptografía (Kriptos=ocultar, Graphos=escritura) la
técnica de transformar un mensaje inteligible, denominado
texto en claro, en otro que sólo puedan entender las personas
autorizadas a ello, que llamaremos criptograma o texto cifrado.
El método o sistema empleado para encriptar el texto en claro
se denomina algoritmo de encriptación.
La
Criptografía
es una rama de las Matemáticas, que se complementa con el
Criptoanálisis, que es la técnica de descifrar textos
cifrados sin tener autorización para ellos, es decir, realizar
una especie de Criptografía inversa. Ambas técnicas
forman la ciencia llamada Criptología.
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | Ñ | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| D | E | F | G | H | I | J | K | L | M | N | Ñ | O | P | Q | R | S | T | U | V | W | X | Y | Z | A | B | C |
Por
lo que el mensaje "HOLA MUNDO" se transformaría
en "KRÑD OXPGR". Para volver al mensaje original
desde el texto cifrado tan sólo hay que coger un alfabeto
e ir sustituyendo cada letra por la que está tres posiciones
antes en el msimo.
Este
sistema fué innovador en su época, aunque en realidad
es fácil de romper, ya en todo sistema de trasposición
simple sólo hay un número de variaciones posible
igual al de letras que formen el alfabeto (27 en este caso).
Este
fué el primer sistema criptográfico conocido, y a
partir de él, y a lo largo de las historia, aparecierón
otros muchos sitemas, basados en técnicas criptológicas
diferentes. Entre ellos caben destacar los sistemas monoalfabéticos
(parecidos al de Julio Cesar, pero que tansforman cada letra del
alfabeto original en la correspondiente de un alfabeto desordenado),
el sistema Playfair de Ser Charles Wheastone (1854, sitema monoalfabético
de diagramas), los sistemas polialfabéticos, los de permutación,
etc.
Aunque
han sido muchos, y no vamos a verlos a fondo, sí hay que
destacar dos sistemas generales de ocultación, ya que juntos
forman la base de muchos de los sistemas criptográficos actuales.
Son la sustitución y la permutación.
La
sustitución consiste
en cambiar los caracteres componentes del mensaje original
en otros según una regla determinada de posición natural
en el alfabeto. Por ejemplo, fijar una equivalencia entre las letras
del alfabeto original y una variación de él, de forma
análoga a lo que ocurre en el método de Julio Cesar.
Si fijamos la equivalencia de alfabetos:
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | Ñ | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| J | K | L | M | N | Ñ | O | P | Q | R | S | T | U | V | W | X | Y | Z | A | B | C | D | E | F | G | H | I |
No
es necesario que el albafeto equivalente esté ordenado naturalmente,
si no que puede estar en cualquier otro orden. Sólo se
exije que tenga todos y cada uno de los elementos del alfabeto
original.
La
trasposición en
cambio consiste en cambiar los caracteres componentes del
mensaje original en otros según una regla determinada de posición
en el orden del mensaje. Por ejemplo, si establecemos la
siguiente
regla de cambio en el orden de las letras en el texto:
| La letra |
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
| pasar a ser la |
5
|
1
|
4
|
7
|
8
|
2
|
8
|
3
|
6
|
Tanto
la sustitución como la trasposición son técnicas
básicas para ocultar la redundancia en un texto plano, redundancia
que se transmite al texto cifrado, y que puede ser el punto de partida
para un ataque por Criptoanálisis. La redundancia es el hecho
de que casi todos los símbolos de un mensaje en lenguaje
natural contienen información que se puede extraer de los
símbolos que le rodean.
El
problema inmediato que se plantéa en cualquier sistema complejo, tanto
de sustitución como de permutación, es recordar el
nuevo orden que hemos establecido para obtener el mensaje camuflado,
problema tanto más dificil de resolver cuento más
complicado haya sido el sistema elegido.
Una
solución sería escribir en un soporte cualquiera (papel,
disquete, etc.) éste nuevo orden, pero siempre queda entonces
el nuevo problema de guardar el soporte, ya que si cae en manos
extrañas dará al traste con el mecanismo de ocultación.
Mejor
solución es implementar un mecanismo de sustitución
o de permutación basado en una palabra o serie fácil
de recordar. Por ejemplo, podemos establecer un mecanismo criptográfico
que se base en una palabra corta. Consideremos que queremos cifrar
la frase "HOLA MUNDO" basándonos en la palabra
"HTML". Para ello escribimos una tabla o matriz con tantas
columnas como letras tenga la palabra elegida, y colocamos en la
fila superior dicha palabra. El mensaje a cifrar lo vamos situando
en las filas siguientes consecutívamente y si sobran celdas
las dejamos vacías:
|
H
|
T
|
M
|
L
|
|
H
|
O
|
L
|
A
|
|
M
|
U
|
N
|
D
|
|
O
|
|
|
|
El
paso siguiente será cambiar el orden de las filas, por ejemplo
ordenando la palabra elegida en orden alfabético, con
lo que nuestra tabla nos queda:
|
H
|
L
|
M
|
T
|
|
H
|
A
|
L
|
O
|
|
M
|
D
|
N
|
U
|
|
O
|
|
|
|
|
H
|
H
|
M
|
O
|
|
L
|
A
|
D
|
|
|
M
|
L
|
N
|
|
|
O
|
|
|
|
El
uso de una palabra o serie determinada como base de un sistema
de cifrado
posée la ventaja de que, si el sistema es complejo, tan sólo
será facil obtener el texto en claro a quién sepa
dicha palabra, además de ser fácil de recordar.
Esta palabra o serie base del mecanismo de cifrado se denomina clave
de cifrado, y el número de letras que la forman se
llama longitud de la clave.
Indudablemente,
cuanto más complicado sea el mecanismo de cifrado y cuanto
más larga sea la clave, más dificil será romper
el sistema y obtener el mensaje original para un extraño.
Pero más complicado será también para el
destinatario del mensaje cifrado realizar las operaciones de
descifrado y obtener
el mensaje original, por lo que se crea el dilema seguridad /
tiempo.
Las
claves de encriptación van a ser la base fundamental de los
modernos sistemas criptográficos, basados en operaciones
matemáticas generalmente muy complejas.
Como
hemos visto en el apartado anterior, los sistemas criptográficos
clásicos presentaban una dificultad en cuanto a la relación
complejidad-longitud de la clave / tiempo necesario para encriptar
y desencriptar el mensaje.
velocidad
de cálculo: con
la aparición de los computadores se dispuso de una potencia
de cálculo muy superior a la de los métodos clásicos.
necesidades
de seguridad: surgieron
muchas actividades nuevas que precisaban la ocultación de
datos, con lo que la Criptología experimentó un
fuerte avance.
A
partir de estas bases surgieron nuevos y complejos sistemas
criptográficos,
que se clasificaron en dos tipos o familias principales, los de
clave simétrica y los de clave pública. Los modernos
algoritmos de encriptación simétricos mezclan la trasposición
y la permutación, mientras que los de clave pública
se basan más en complejas operaciones matemáticas.
Incluye
los sistemas clásicos, y se caracteriza por que en ellos
se usa la misma clave para encriptar y para desencriptar, motivo
por el que se denomina simétrica.
 |
Toda
la seguridad de este sistema está basada en la llave simétrica,
por lo que es misión fundamental tanto del emisor como del
receptor conocer esta clave y mantenerla en secreto. Si la llave
cáe en manos de terceros, el sistema deja de ser seguro,
por lo que habría que desechar dicha llave y generar una
nueva.
Conocidos
el texto en claro y el texto cifrado debe resultar más caro
en tiempo o dinero descifrar la clave que el valor posible de la
información obtenida por terceros.
Generalmente
el algoritmo de encriptación es conocido, se divulga públicamente,
por lo que la fortaleza del mismo dependerá de su complejidad
interna y sobre todo de la longitud de la clave empleada, ya que
una de las formas de criptoanálisis primario de cualquier
tipo de sistema es la de prueba-ensayo, mediante la que se van
probando
diferentes claves hasta encontrar la correcta.
Los
algoritmos simétricos encriptan bloques de texto del documento
original, y son más sencillos que los sistemas de clave pública,
por lo que sus procesos de encriptación y desencriptación
son más rápidos.
Todos
los sistemas criptográficos clásicos se pueden considerar
simétricos, y los principales algoritmos simétricos
actuales son DES, IDEA y RC5. Actualemente
se está llevando a cabo un proceso de selección para
establecer un sistema simétrico estándar, que se
llamará
AES (Advanced Encryption Standart), que se quiere que sea
el nuevo sistema que se adopte a nivel mundial.
Las
principales desventajas de los métodos simétricos
son la distribución de las claves, el peligro de que muchas
personas deban conocer una misma clave y la dificultad de almacenar
y proteger muchas claves diferentes.
También
llamada asimétrica, se basa en el uso de dos claves diferentes,
claves que poséen una propiedad fundamental: una clave
puede desencriptar lo que la otra ha encriptado.
Generalmente
una de las claves de la pareja, denominada clave privada, es
usada
por el propietario para encriptar los mensajes, mientras que
la otra, llamada clave pública, es usada para desencriptar
el mensaje cifrado.
Los
algoritmos asimétricos están basados en funciones
matemáticas fáciles de resolver en un sentido, pero
muy complicadas de realizar en sentido inverso, salvo que se conozca
la clave privada, como la potencia y el logaritmo. Ambas claves,
pública y privada, están relacionadas matemáticamente,
pero esta relación debe ser lo suficientemente compleja como
para que resulte muy dificil obtener una a partir de la otra. Este
es el motivo por el que normalmente estas claves no las elige el
usuario, si no que lo hace un algoritmo específico para ello,
y suelen ser de grán longitud.
Mientras
que la clave privada debe mantenerla en secreto su propietario,
ya que es la base de la seguridad del sistema, la clave pública
es difundida ámpliamente por Internet, para que esté
al alcance del mayor número posible de personas, existiendo
servidores que guardan, administran y difunden dichas claves.
En
este sistema, para enviar un documento con seguridad, el emisor
(A) encripta
el mismo con la clave pública del receptor (B) y lo envía
por el medio inseguro. Este documento está totalmente protegido
en su viaje, ya que sólo se puede desencriptar con la clave
privada correspondiente, conocida sólamente por B. Al
llegar el mensaje cifrado a su destino, el receptor usa su clave
privada
para obtener el mensaje en claro.
Una
variación de este sistema se produce cuando es el emisor
A el que encripta un texto con su clave privada, enviando por el
medio inseguro tanto el mensaje en claro como el cifrado. Así,
cualquier receptor B del mismo puede comprobar que el emisor a sido
A, y no otro que lo suplante, con tan sólo desencriptar el
texto cifrado con la clave pública de A y comprobar que coincide
con el texto sin cifrar. Como sólo A conoce su clave privada,
B puede estar seguro de la autenticidad del emisor del mensaje.
Este sistema de autentificación de denomina firma digital,
y lo estudiaremos después con más detenimiento.
 |
conocido
el texto cifrado (criptograma) y el texto en claro debe resultar
más caro en tiempo o dinero descifrar la clave que el valor
posible de la información obtenida por terceros.
La
principal ventaja de los sistemas de clave pública frente a los simétricos
es que la clave pública y el algoritmo de cifrado son o pueden
ser de dominio público y que no es necesario poner en peligro
la clave privada en tránsito por los medios inseguros, ya
que ésta está siempre oculta y en poder únicamente
de su propietario. Como desventaja, los sistemas de clave pública
dificultan la implementación del sistema y son mucho más
lentos que los simétricos.
Generalmente,
y debido a la lentitud de proceso de los sistemas de llave
pública,
estos se utilizan para el envío seguro de claves simétricas,
mientras que éstas últimas se usan para el envío
general de los datos encriptados.
El
primer sistema de clave pública que apareción fué
el de Diffie-Hellman, en 1976, y fué la base para el desarrollo
de los que después aparecieron, entre los que cabe destacar
el RSA (el más utilizado en la actualidad).
Los
principales sistemas criptográficos, tanto de clave simétrica
como pública, los veremos con más detenimiento más
adelante.
En
muchas ocasiones se implementan sistemas criptográficos mixtos,
en los que se usa la llave pública del receptor para encriptar
una clave simétrica que se usará en el proceso de
comunicación encriptada. De esta forma se aprovechan las
ventajas de ambos sistemas, usando el sistema asimétrico
para el envío de la clave sensible y el simétrico,
con mayor velocidad de proceso, para el envío masivo de
datos.
Es
desordenar un mensaje con una fórmula matemática complicada volviéndola
ilegible a cualquiera, excepto al creador del mensaje y las
personas
que tengan la clave secreta para decodificarla.
La
encriptación
garantiza la confidencialidad, la integridad y la autenticidad de
la información que se desea transmitir. El principal dilema
que tiene es que posee dos contra cara: la buena y la mala. La buena
es la de asegurar la confidencialidad del mensaje, mientras que
la mala es que esta misma confidencialidad está a disposición
de los delincuentes de todo el mundo para comunicarse sin ser
detectados.
SSL
(Secure Sockets Layer) está siendo desarrollado por Netscape
para establecer conexiones seguras a servidores. PGP (Pretty Good
Privacy), cifra y descifra datos de todo tipo, y muy útil
en el correo electrónico. IDEA ( International Data Encryption
Algorithm)
Se
refiere a la exactitud o corrección de los datos en la base de datos.
Los guardados en la base de datos deben de estar protegidos contra
los accesos no autorizados, de la destrucción o alteración
mal intencionada y de la introducción accidental de inconsistencias.
El mal uso de la base de datos puede clasificarse como malintencionada
(con premeditación)o accidental.
- Caídas durante el procesamiento de transacciones
- Anomalías causadas por el acceso concurrente a la base de datos
- Anomalías causadas por la distribución de datos entre varias computadoras
-
Errores lógicos que violan la suposición de que las transacciones conservan las ligaduras de consistencia de la base de datos. Es mas sencilla la protección contra la perdida accidental de la consistencia de los datos que la protección contra el acceso mal intencionado a la base de datos.
- La lectura no autorizada de los datos (robo de información)
- La modificación no autorizada de los datos
- La
destrucción no autorizada de los datos.
CONCEPTO
1.Las restricciones de integridad proporcionan un medio de
asegurar
que los cambios que se hacen en la base de datos por usuarios
autorizados no resultan en una perdida de consistencia de los
datos. Así,
pues, las restricciones de integridad protegen la base de datos
contra daños accidentales.
Una
restricción de integridad puede ser un predicado arbitrario
perteneciente a la base de datos. Sin embargo, los predicados arbitrarios
pueden ser costosos de probar. Así, normalmente nos limitamos
a restricciones de integridad que pueden probarse con un mínimo
de tiempo extra.
CONCEPTO
2. Una vez definida la estructura de datos del modelo relacional,
pasamos a estudiar las reglas de integridad que los datos almacenados
en dicha estructura deben cumplir para garantizar que son correctos.
Hay
además reglas de integridad muy importantes que son
restricciones que se deben cumplir en todas las bases de datos
relacionales y
en todos sus estados o instancias (las reglas se deben cumplir
todo el tiempo).
Al
definir cada atributo sobre un dominio se impone una restricción
sobre un conjunto de valores permitidos para cada atributo.
A este
tipo de restricciones se le denomina restricciones de dominio
Los
limites de dominios son la forma más elemental de restricciones
de integridad. Son fáciles de probar por el sistema siempre
que se introduce un nuevo dato en la base de datos.
Es
posible que varios atributos tengan el mismo dominio. Las restricciones
de dominio no solo nos permite probar valores insertados en
la base
da datos sino que también nos permite probar consultas para
asegurar que la comparación que se hace tiene sentido.
- Cadena de caracteres de longitud fija, con longitud especificada por el usuario.
- Numero en coma fija, con precisión especificada por el usuario.
- Entero (un subconjunto finito de los enteros que es dependiente de la maquina)
- Entero pequeño (un subconjunto del tipo de dominio entero dependiente de la maquina).
- Números en coma flotante y en coma flotante de doble precisión, con precisión dependiente de la maquina.
El
SQL estándar permite que la declaración del dominio de
un atributo incluya la especificación not null . Cualquier
modificación de la base de datos que causara que se insertase
un valor nulo en un dominio not null genera un diagnóstico
de error.
Se
aplica a las claves ajenas si en una relación hay alguna
clave ajena, sus valores deben coincidir con los valores de
la clave primaria
a la que hace referencia o bien deben ser completamente nulos.
Existen
2 opciones rechazar la operación o bien aceptar la operación
y realizar operaciones adicionales compensatorias que conduzcan
a un estado legal.
Una
vista es una forma de proporcionar al usuario un modelo personalizado
de la base de datos. Aunque es imposible impedir que un usuario
tenga acceso directo a una relación, puede permitírsele
acceso a parte de esa relación por medio de una vista.
Al
diseñar
una base de datos SQL Server, se deben tener en cuenta varios factores,
que incluyen los archivos de la base de datos y grupos de archivos,
registros de transacciones, la instalación del SQL Server
y su ambiente operativo, y la seguridad. Esta lección
discute cada uno de estos temas.
Para
definir una base de datos, SQL Server 2000 usa un conjunto de archivos
del sistema operativo. Todos los datos y objetos de la base de datos,
como tablas, procedimientos almacenados, desencadenadores, y vistas,
se guardan dentro de los siguientes tipos de archivos del sistema
operativo:
-
Archivo Primario. Este archivo contiene la información de arranque para la base de datos y es usado para almacenar datos. Cada base de datos tiene un archivo de los datos primario.
-
Archivo Secundario. Estos archivos mantienen todos los datos que no caben en el archivo de los datos primario. Si el archivo primario puede almacenar todos los datos da la base de datos, las bases de datos no necesitan tener archivos de los datos secundarios. Algunas bases de datos podrían ser lo suficientemente grandes para necesitar archivos de datos secundarios múltiples o usar archivos secundarios en unidades de disco separadas para distribuir datos en múltiples discos o para mejorar el rendimiento de la base de datos.
-
Registros de transacciones. Estos archivos mantienen la información del registro que se usa para recuperar la base de datos. Debe haber por lo menos un archivo de registro para cada base de datos.
Una
base de datos simple puede crearse con un archivo primario
que contiene
todos los datos y objetos y un archivo de registro que contiene
la información del registro de transacciones.
Alternativamente,
una base de datos más compleja puede crearse con un archivo
primario y cinco archivos secundarios. Los datos y objetos de la
base de datos son distribuidos por los seis archivos, y cuatro archivos
de registro adicionales contienen la información del registro
de transacciones.
Los grupos de archivos agrupan archivos para propósitos administrativos y de ubicación de datos. Por ejemplo, tres archivos (Data1.ndf, Data2.ndf, y Data3.ndf) pueden crearse en tres unidades de disco y pueden asignarse al grupo de archivos fgroup1. Una tabla puede crearse entonces específicamente en el grupo de archivos fgroup1. Las consultas sobre los datos de la tabla se extenderán por los tres discos y se mejorará el rendimiento. La misma mejora de rendimiento puede lograrse con un solo archivo creado sobre un arreglo redundante de discos independientes (RAID).
Los grupos de archivos agrupan archivos para propósitos administrativos y de ubicación de datos. Por ejemplo, tres archivos (Data1.ndf, Data2.ndf, y Data3.ndf) pueden crearse en tres unidades de disco y pueden asignarse al grupo de archivos fgroup1. Una tabla puede crearse entonces específicamente en el grupo de archivos fgroup1. Las consultas sobre los datos de la tabla se extenderán por los tres discos y se mejorará el rendimiento. La misma mejora de rendimiento puede lograrse con un solo archivo creado sobre un arreglo redundante de discos independientes (RAID).
Los
archivos y grupos de archivos, sin embargo, ayudan a agregar
nuevos
archivos fácilmente a los nuevos discos. Adicionalmente,
si su base de datos excede el tamaño del máximo
para un solo archivo Windows NT, usted puede usar un archivo
de datos
secundario para permitir el crecimiento de su base de datos.
-
Un archivo o grupo de archivos no puede ser usado por más de una base de datos. Por ejemplo, los archivos que ventas.mdf y ventas.ndf que contienen datos y objetos de la base de datos de ventas no pueden ser usados por cualquier otra base de datos.
- Un archivo puede ser un miembro de sólo un grupo de archivos.
- Los datos y la información de registro de transacción no pueden ser parte del mismo archivo o grupo de archivos.
- Los archivos de registro de transacciones nunca son parte de un grupo de archivos.
Una
base de datos comprende un grupo de archivos primario y varios
grupos
de archivo definidos por el usuario. El grupo de archivos que
contiene el archivo primario es el grupo de archivos primario.
Cuando una
base de datos se crea, el grupo de archivos primario contiene
el archivo de datos primario y cualquier otro archivo que no
se pone
en otro grupo de archivos. Todas las tablas del sistema se asignan
en el grupo de archivos primario. Si el grupo de archivos primario
se queda sin espacio, ninguna información nueva del catálogo
puede agregarse a las tablas del sistema. El grupo de archivos primario
sólo se llenará si la bandera de configuración
"autogrow" está apagada o si todos los discos que
están sosteniendo los archivos en el grupo de archivos primario
se quedaron sin espacio. Si sucede esto, se deberá encender
la bandera de configuración "autogrow" o mover
archivos a un nuevo almacenamiento para liberar mas espacio.
Los
grupos de archivos definidos por el usuario son cualquier grupo
de archivos que son específicamente creados por el usuario
cuando él o ella están inicialmente creando o posteriormente
alterando la base de datos. Si un grupo de archivos definido por
el usuario se llena, se afectarán sólo las tablas
de los usuarios específicamente asignadas a ese grupo
de archivos.
En cualquier momento, un grupo de archivos puede ser designado como el grupo de archivos predefinido. Cuando se crean objetos en la base de datos sin especificar a que grupo de archivos pertenecen, se asignan al grupo de archivos predefinido. Los grupos de archivos predefinidos deben ser suficiente grandes para almacenar cualquier objeto no asignado a un grupo de archivos definido por el usuario. Inicialmente, el grupo de archivos primario es el grupo de archivos predefinido.
En cualquier momento, un grupo de archivos puede ser designado como el grupo de archivos predefinido. Cuando se crean objetos en la base de datos sin especificar a que grupo de archivos pertenecen, se asignan al grupo de archivos predefinido. Los grupos de archivos predefinidos deben ser suficiente grandes para almacenar cualquier objeto no asignado a un grupo de archivos definido por el usuario. Inicialmente, el grupo de archivos primario es el grupo de archivos predefinido.
Los
grupos de archivos predefinidos pueden ser cambiados usando
la sentencia
ALTER DATABASE. Cuando usted cambia el grupo de archivos predefinido,
cualquier objeto que no tiene un grupo de archivos especificado
se asigna a los archivos de los datos en el nuevo grupo de
archivos
predefinido cuando se crea. La asignación para los objetos
y tablas del sistema, sin embargo, se mantiene en el grupo de
archivos
primario y no en el nuevo grupo de archivos predefinido.
Cambiar el grupo de archivos predefinido previene que objetos del usuario que no se crean específicamente en un grupo de archivos definidos por el deban competir con los objetos y tablas del sistema para el espacio de los datos.
Cambiar el grupo de archivos predefinido previene que objetos del usuario que no se crean específicamente en un grupo de archivos definidos por el deban competir con los objetos y tablas del sistema para el espacio de los datos.
-
La mayoría de las bases de datos trabajará bien con un solo archivo del datos y un solo archivo de registro de transacciones.
-
Si usted usa archivos múltiples, cree un segundo grupo de archivos para los archivos adicionales y configúrelo como el grupo de archivos predefinido. De esta manera, el archivo primario contendrá sólo tablas y objetos del sistema.
-
Para maximizar rendimiento, usted puede crear archivos o grupos de archivos en tantos discos físicos locales disponibles como sea posible, y ubicar grandes objetos que compiten por espacio en grupos de archivos diferentes.
- Use grupos de archivos para habilitar la colocación de objetos en discos físicos específicos.
-
Ubique las diferentes tablas que se usan para una misma consulta en grupos de archivos diferente. Este procedimiento mejorará el rendimiento al tomar ventaja del procesamiento paralelo de input/output del disco (I/O) al buscar datos vinculados.
-
Ponga las tablas fuertemente accedidas y los índices no-agrupados que pertenecen a esas tablas en grupos de archivos diferentes. Este procedimiento mejorará el rendimiento debido al I/O paralelo si los archivos se localizan en discos físicos diferentes.
- No ponga el archivo de registro de transacciones en el mismo disco físico con los otros archivos y grupos de archivos.
Una
base de datos en SQL Server 2000 tiene por lo menos un archivo
de
datos y un archivo de registro de transacciones. Los datos y
la información del registro de transacciones nunca es mezclada
en el mismo archivo, y archivos individuales son sólo por
una única base de datos.
El
SQL Server usa el registro de transacciones de cada base de
datos
para recuperar transacciones. El registro de transacciones es
un registro serial de todas las modificaciones que han ocurrido
en
la base de datos así como de las transacciones que realizaron
dichas modificaciones. El archivo de registro de transacciones graba
el comienzo de cada transacción y archiva los cambios producidos
en los datos. Este registro tiene bastante información para
deshacer las modificaciones (si es necesario) que hizo durante cada
transacción. Para algunas operaciones pesadas, como CREATE
INDEX, el registro de transacciones registra, en cambio, los hechos
a los que la operación dio lugar. El registro crece continuamente
tanto como operaciones ocurran en la base de datos.
El registro de transacciones graba la asignación y liberación de las páginas y la grabación definitiva (commit) o la vuelta atrás (rollback) de cada transacción. Este capacidad permite al SQL Server rehacer (Rollup) o deshacer (Rollback) cada transacción de las siguientes maneras:
El registro de transacciones graba la asignación y liberación de las páginas y la grabación definitiva (commit) o la vuelta atrás (rollback) de cada transacción. Este capacidad permite al SQL Server rehacer (Rollup) o deshacer (Rollback) cada transacción de las siguientes maneras:
-
Una transacción es rehecha cuando se aplica un registro de transacciones. El SQL Server copia la imagen posterior a cada modificación de la base de datos o vuelve a ejecutar sentencias como CREATE INDEX. Estas acciones se aplican en el mismo orden en la que ellas ocurrieron originalmente. Al final de este proceso, la base de datos está en el mismo estado que estaba en el momento en que el registro de transacciones fue copiado.
-
Una transacción se deshace cuando una transacción queda incompleta por alguna causa. El SQL Server copia la imagen previa de todas las modificaciones a la base de datos desde el BEGIN TRANSACTION. Si encuentra archivos de registro de transacciones que indican que un CREATE INDEX fue ejecutado, realiza operaciones que lógicamente invierten la sentencia. Éstos imágenes previas Ye inversiones del comando CREATE INDEX son aplicados en orden inverso a la secuencia original.
A
un punto de salvaguarda, el SQL Server asegura que se han grabado
en
el disco todos los archivos de registro de transacciones y las
páginas
de la base de datos que se modificaron. Durante cada proceso de
recuperación de base de datos, que ocurre cuando el SQL Server
se reinicia, una transacción necesita ser rehecha sólo
si no se conoce si todas las modificaciones de datos de la transacción
fueron realmente transferidas desde el caché de SQL Server
al disco. Debido a que en un punto de salvaguarda se obliga a que
todas las páginas modificadas sean efectivamente grabadas
en el disco, este representa el punto que se toma como punto de
inicio para el comienzo de las operaciones de recuperación.
Dado que para todas las páginas modificadas antes del punto
de salvaguarda se garantiza que están en el disco, no
hay ninguna necesidad de rehacer algo que se hizo antes del punto
de
salvaguarda.
Las
copias de respaldo del registro de transacciones le permiten
a usted
que recupere la base de datos al momento de un punto específico
(por ejemplo, previo a entrar en datos no deseados) o a un punto
de falla. Las copias de respaldo del registro de transacciones deben
ser tenidas muy en cuenta dentro de su estrategia de recuperación
de bases de datos.
Generalmente,
cuanto más grande es la base de datos, mayores son los requisitos
de hardware. El diseño de la base de datos siempre debe tomar
en cuenta la velocidad del procesador, el tamaño de la memoria,
y el espacio del disco duro y su configuración. Hay otros
factores determinantes, sin embargo: el número de usuarios
o sesiones coexistentes, el registro de transacciones, y los tipos
de operaciones a realizar sobre la base de datos. Por ejemplo, una
base de datos que contiene datos de la biblioteca escolar con escasos
niveles de actualización generalmente tendrá requisitos
de hardware más bajos que un almacén de datos de un-terabyte
que contiene ventas, productos, e informaciones de los clientes
frecuentemente analizados, para una gran corporación. Aparte
de los requisitos de almacenamiento de disco, se necesitará
más memoria y procesadores más rápidos para
levantar en memoria grandes volúmenes de datos del almacén
de datos y procesar mas rápidamente las consultas.
Al
diseñar
una base de datos, usted podría necesitar estimar cuán
grande será la base de datos cuando este llena de información.
Estimar el tamaño de la base de datos puede ayudarle a determinar
la configuración del hardware que usted necesitará para
alcanzar los siguientes requisitos:
- Lograr el rendimiento requerido por sus aplicaciones
- Asegurar la cantidad física apropiada de espacio en disco para guardar los datos y índices
Estimar
el tamaño de una base de datos también puede llevarlo
a determinar si el diseño de la base de datos necesita mayor
refinamiento. Por ejemplo, usted podría determinar que el
tamaño estimado de la base de datos es demasiado grande para
ser implementada en su organización y que requiere mayor
normalización. Recíprocamente, el tamaño estimado
podría ser más pequeño que el esperado,
permitiendo denormalizar en cierto grado la base de datos para
mejorar el rendimiento
de las consultas.
Para
estimar el tamaño de una base de datos, estime el tamaño
de cada tabla individualmente y sume dichos valores. El tamaño
de una tabla depende si la tabla tiene o no índices y, en
este caso, qué tipo de índices.
Diseño físico de la base de datos
Diseño físico de la base de datos
El
subsistema de entrada/salida (motor de almacenamiento) es un
componente importante
de cualquier base de datos relacional. Una aplicación de
base de datos exitosa normalmente requiere una planificación
cuidadosa en las fases tempranas de su proyecto. El motor de almacenamiento
de una base de datos relacional requiere de esta planificación
que incluye a lo siguiente:
- Qué tipo de hardware de disco será utilizado
- Cómo distribuye sus datos en los discos
- Qué diseño de índices se va a utilizar para mejorar el rendimiento de las consultas.
- Cómo se van a configurar apropiadamente todos los parámetros de configuración
- para que la base de datos funcione correctamente.
Aunque
la instalación de SQL Server está más allá
del alcance de este trabajo, siempre debe tener en cuenta lo siguiente
antes de realizar una instalación:
- Esté seguro que la computadora reúne los requisitos de sistema para SQL Server 2000
-
Haga copias de respaldo de su instalación actual de Microsoft SQL Server si usted está instalando SQL Server 2000 en la misma computadora.
-
Si usted está instalando un failover cluster, desactive el NetBIOS en todas las tarjetas de la red privada antes de ejecutar el instalador de SQL Server.
-
Repase todas las opciones de instalación de SQL Server y este preparado para hacer las selecciones apropiadas cuando ejecute el instalador.
-
Si usted está usando un sistema operativo que tiene configuraciones regionales diferentes a inglés (Estados Unidos), o si usted está personalizando el juego de caracteres o la configuración del ordenamiento de los caracteres, revise los temas referidos a la configuración de colecciones.
Antes
de ejecutar el instalador de SQL Server 2000, cree uno o más
cuentas de usuario del dominio si usted está instalando
SQL Server 2000 en una computadora con Windows NT o Windows 2000
y quiere
que SQL Server 2000 se comunique con otros clientes y servidores.
Usted
debe iniciar el sistema operativo bajo una cuenta de usuario
que
tiene permisos locales de administrador; por otra parte, usted
debe asignar los permisos apropiados a la cuenta de usuario
de dominio.
Esté seguro de cerrar todos los servicios dependientes sobre
SQL Server (incluso cualquier servicio que usa ODBC, como el Internet
Information Server, o IIS). Además, cierre al Windows
NT Event Viewer y a los visualizadores de la registry (Regedit.exe
o Regedt32.exe).
Seguridad
Seguridad
Una
base de datos debe tener un sistema de seguridad sólido para
controlar las actividades que pueden realizarse y determinar qué
información puede verse y cuál puede modificarse.
Un sistema de seguridad sólido asegura la protección
de datos, sin tener en cuenta cómo los usuarios obtienen
el acceso a la base de datos.
Un
plan de seguridad identifica qué usuarios pueden ver qué
datos y qué actividades pueden realizar en la base de
datos. Usted debe seguir siguientes los pasos para desarrollar
un plan
de seguridad:
- Liste todas los items y actividades en la base de datos que debe controlarse a través de la seguridad.
- Identifique los individuos y grupos en la compañía.
-
Combine las dos listas para identificar qué usuarios pueden ver qué conjuntos de datos y qué actividades pueden realizar sobre la base de datos.
Un
usuario atraviesa dos fases de seguridad al trabajar en SQL
Server: la autenticación
y autorización (aprobación de los permisos). La fase
de la autenticación identifica al usuario que está
usando una cuenta de inicio de sesión y verifica sólo
su capacidad para conectarse a un instancia de SQL Server. Si la
autenticación tiene éxito, el usuario se conecta a
una instancia de SQL Server. El usuario necesita entonces permisos
para acceder a las bases de datos en el servidor, lo que se obtiene
concediendo acceso a una cuenta en cada base de datos (asociadas
al inicio de sesión del usuario). La validación
de los permisos permite controlar las actividades que el usuario
puede
realizar en la base de datos SQL Server.
El
SQL Server puede operar en uno de dos modos de seguridad (autenticación):
la Autenticación de Windows y el modo Mixto. El modo de Autenticación
de Windows le permite a un usuario que se conecte a través
de una cuenta de usuario Windows NT 4.0 o Windows 2000. El modo
mixto (Autenticación de Windows y Autenticación de
SQL) le permite a los usuarios que conecten a una instancia de SQL
Server usando Autenticación de Windows o Autenticación
de SQL Server. Los usuarios que se conectan a través de una
cuenta del usuario Windows NT 4.0 o Windows 2000 pueden hacer uso
de conexiones de confianza en el modo de Autenticación
de Windows o en el modo mixto.
Al
diseñar
una base de datos SQL Server, se deben tener en cuenta varios factores,
que incluyen los archivos de la base de datos y grupos de archivos,
registros de transacciones, la instalación del SQL Server
y su ambiente operativo, y la seguridad.
Todos
los datos y objetos de la base de datos, como tablas, procedimientos
almacenados (Store Procedure), desencadenadores (Triggers),
y vistas
(View), se guardan dentro de los archivos primario, secundarios,
dentro del registro de transacciones. Los grupos de archivos
agrupan
archivos para propósitos administrativos y de ubicación
de los datos. El grupo de archivos que contiene el archivo primario
es el grupo de archivos primario. Una base de datos en SQL Server
2000 tiene al menos un archivo de datos y un archivo de registro
de transacciones. Datos y la información del registro de
transacciones nunca se mezclan en el mismo archivo, y los archivos
individuales son utilizados por solo una base de datos. El SQL Server
usa el registro de transacciones de cada base de datos para recuperar
transacciones. El diseño de la base de datos siempre debe
tomar en consideración la velocidad de procesador, la memoria,
y el espacio del disco duro y su configuración. Hay otros
factores determinantes, sin embargo: el número de usuarios
o sesiones coexistentes, el registro de transacciones, y los tipos
de operaciones a realizar sobre la base de datos Al diseñar
una base de datos, usted podría necesitar estimar cuán
grande será la base de datos cuando este llena de información.
Al instalar SQL Server, usted debe tener en cuenta varios problemas.
Una base de datos debe tener un sistema de seguridad sólido
para controlar las actividades que pueden o no realizarse y determinar
qué información puede verse y cuál puede modificarse.
Un diseño de seguridad identifica qué usuarios pueden
ver qué datos y qué actividades pueden realizar
sobre la base de datos.