![]()
| Introducción | ||||||||||||||||||||||||||||
|
Desde
tiempos remotos, los datos han sido registrados por el hombre
en algún tipo de soporte (piedra, papel, madera, etc.)
a fin de que quedara constancia de un fenómeno o idea.
Los datos han de ser interpretados para que se conviertan en información
útil, esta interpretación supone un fenómeno
de agrupación y clasificación. |
||||||||||||||||||||||||||||
|
En
la era actual y con el auge de los medios informáticos
aparece el almacenamiento en soporte electromagnético,
ofreciendo mayores posibilidades de almacenaje, ocupando menos
espacio y ahorrando un tiempo considerable en la búsqueda
y tratamiento de los datos. Es en este momento donde surge el
concepto de bases de datos y con ellas las diferentes metodologías
de diseño y tratamiento.
|
||||||||||||||||||||||||||||
|
El
objetivo básico de toda base de datos es el almacenamiento
de símbolos, números y letras carentes de un significado
en sí, que con un tratamiento adecuado se convierten en
información útil. Un ejemplo podría ser el
siguiente dato: 19941224, con el tratamiento correcto podría
convertirse en la siguiente información: "Fecha de
nacimiento: 24 de diciembre de 1994".
|
||||||||||||||||||||||||||||
|
Según
van evolucionando los tiempos, las necesidades de almacenamiento
de datos van creciendo y con ellas las necesidades de transformar
los mismos datos en información de muy diversa naturaleza.
Esta información es utilizada diariamente como herramientas
de trabajo y como soporte para la toma de decisiones por un gran
colectivo de profesionales que toman dicha información
como base de su negocio. Por este motivo el trabajo del diseñador
de bases de datos es cada vez más delicado, un error en
el diseño o en la interpretación de datos puede
dar lugar a información incorrecta y conducir al usuario
a la toma de decisiones equivocadas. Se hace necesario la creación
de un sistema que ayude al diseñador a crear estructuras
correctas y fiables, minimizando los tiempos de diseño
y explotando todos los datos, nace así la metodología
de diseño de bases de datos.
|
||||||||||||||||||||||||||||
| La metodología de diseño de datos divide cada modelo en tres esquemas: | ||||||||||||||||||||||||||||
|
A)
Modelo Global: se trata de una representación gráfica
legible por el usuario y que nos aporta el flujo de información
dentro de una organización. No existen reglas para su construcción
y se debe realizar siempre el esquema más sencillo posible
para la comprensión por parte del usuario de la base de
datos. Por ejemplo:
|
||||||||||||||||||||||||||||
|
B)
Modelo Lógico: se trata de una representación gráfica,
mediante símbolos y signos normalizados, de la base de
datos. Su objetivo es representar la estructura de los datos y
las dependencias de los mismos, garantizando la consistencia y
evitando la duplicidad. Este modelo de datos se estudiará
con profundidad en los capítulos siguientes.
|
||||||||||||||||||||||||||||
|
C)
Modelo Físico: se trata del almacén de los datos,
es la base de datos en sí misma, el soporte donde se almacenan
los datos y de donde se extraen para convertir los datos en información.
En función del gestor de bases de datos empleado las reglas
de almacenamiento varían.
|
||||||||||||||||||||||||||||
| Para introducirnos mas en este tema, empezaremos definiendo que es un modelo. | ||||||||||||||||||||||||||||
|
Modelo:
Es una representación de la realidad que contiene las características
generales de algo que se va a realizar. En base de datos, esta
representación la elaboramos de forma gráfica.
|
||||||||||||||||||||||||||||
| ¿Qué es un modelo de datos? | Volver | |||||||||||||||||||||||||||
| Es una colección de herramientas conceptuales para describir los datos, las relaciones que existen entre ellos, semántica asociada a los datos y restricciones de consistencia. | ||||||||||||||||||||||||||||
| Los modelos de datos se dividen en tres grupos: | ||||||||||||||||||||||||||||
| 1.-
Modelos lógicos basados en objetos. 2.- Modelos lógicos basados en registros. 3.- Modelos físicos de datos. |
||||||||||||||||||||||||||||
| Modelos lógicos basados en objetos. | Volver | |||||||||||||||||||||||||||
|
Se
usan para describir datos en los niveles conceptual y de visión,
es decir, con este modelo representamos los datos de tal forma
como nosotros los captamos en el mundo real, tienen una capacidad
de estructuración bastante flexible y permiten especificar
restricciones de datos explícitamente. Existen diferentes
modelos de este tipo, pero el más utilizado por su sencillez
y eficiencia es el modelo Entidad-Relación.
|
||||||||||||||||||||||||||||
| Modelo Entidad-Relación. | ||||||||||||||||||||||||||||
|
Denominado
por sus siglas como: E-R; Este modelo representa a la realidad
a través de entidades, que son objetos que existen
y que se distinguen de otros por sus características, por
ejemplo: un alumno se distingue de otro por sus características
particulares como lo es el nombre, o el numero de control asignado
al entrar a una institución educativa, así mismo,
un empleado, una materia, etc. Las entidades pueden ser de dos
tipos:
|
||||||||||||||||||||||||||||
| Tangibles: Son todos aquellos objetos físicos que podemos ver, tocar o sentir. | ||||||||||||||||||||||||||||
| Intangibles: Todos aquellos eventos u objetos conceptuales que no podemos ver, aun sabiendo que existen, por ejemplo: la entidad materia, sabemos que existe, sin embargo, no la podemos visualizar o tocar. | ||||||||||||||||||||||||||||
|
Las
características de las entidades en base de datos se llaman
atributos, por ejemplo el nombre, dirección teléfono,
grado, grupo, etc. son atributos de la entidad alumno; Clave,
número de seguro social, departamento, etc., son atributos
de la entidad empleado. A su vez una entidad se puede asociar
o relacionar con más entidades a través de relaciones.
|
||||||||||||||||||||||||||||
| Pero para entender mejor esto, veamos un ejemplo: | ||||||||||||||||||||||||||||
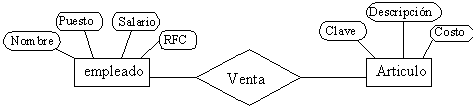
|
Consideremos
una empresa que requiere controlar a los vendedores y las ventas
que ellos realizan; de este problema determinamos que los objetos
o entidades principales a estudiar son el empleado (vendedor)
y el artículo (que es el producto en venta), y las características
que los identifican son:
|
||||||||||||||||||||||||||||
| La relación entre ambas entidades la podemos establecer como Venta. | ||||||||||||||||||||||||||||
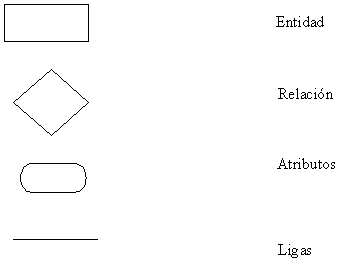
Bueno,
ahora nos falta describir como se representa un modelo E-R gráficamente,
la representación es muy sencilla, se emplean símbolos,
los cuales son:
|
||||||||||||||||||||||||||||
Así
nuestro ejemplo anterior quedaría representado de la siguiente
forma:
|
||||||||||||||||||||||||||||
| Existen más aspectos a considerar con respecto a los modelos entidad relación, estos serán considerados en el tema Modelo Entidad Relación. | ||||||||||||||||||||||||||||
| Modelos lógicos basados en registros. | ||||||||||||||||||||||||||||
|
Se
utilizan para describir datos en los niveles conceptual y físico.Estos
modelos utilizan registros e instancias para representar la realidad,
así como las relaciones que existen entre estos registros
(ligas) o apuntadores. A diferencia de los modelos de datos basados
en objetos, se usan para especificar la estructura lógica
global de la base de datos y para proporcionar una descripción
a nivel más alto de la implementación.
|
||||||||||||||||||||||||||||
Los
tres modelos de datos más ampliamente aceptados son:
|
||||||||||||||||||||||||||||
| Modelo relacional. | ||||||||||||||||||||||||||||
| En
este modelo se representan los datos y las relaciones entre estos,
a través de una colección de tablas, en las cuales
los renglones (tuplas) equivalen a los cada uno de los registros
que contendrá la base de datos y las columnas corresponden
a las características(atributos) de cada registro localizado
en la tupla; Considerando nuestro ejemplo del empleado y el artículo: Tabla del empleado
|
||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||
| Ahora te preguntaras ¿cómo se representan las relaciones entre las entidades en este modelo? | ||||||||||||||||||||||||||||
|
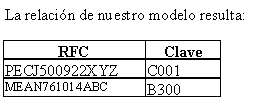
Existen
dos formas de representarla; pero para ello necesitamos definir
que es una llave primaria: Es un atributo el cual definimos como
atributo principal, es una forma única de identificar a
una entidad. Por ejemplo, el RFC de un empleado se distingue de
otro por que los RFC no pueden ser iguales.
|
||||||||||||||||||||||||||||
| Ahora si, las formas de representar las relaciones en este modelo son: | ||||||||||||||||||||||||||||
| 1. Haciendo una tabla que contenga cada una de las llaves primarias de las entidades involucradas en la relación. | ||||||||||||||||||||||||||||
Tomando
en cuenta que la llave primaria del empleado es su RFC, y la llave
primaria del articulo es la Clave.
|
||||||||||||||||||||||||||||
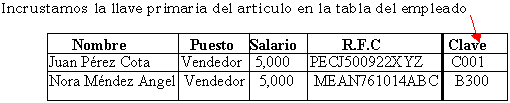
2.
Incluyendo en alguna de las tablas de las entidades involucradas,
la llave de la otra tabla.
|
||||||||||||||||||||||||||||
| Modelo de red. | Volver | |||||||||||||||||||||||||||
|
Este
modelo representa los datos mediante colecciones de registros
y sus relaciones se representan por medio de ligas o enlaces,
los cuales pueden verse como punteros. Los registros se organizan
en un conjunto de gráficas arbitrarias.
|
||||||||||||||||||||||||||||
Ejemplo:
|
||||||||||||||||||||||||||||
| Modelo jerárquico. | Volver | |||||||||||||||||||||||||||
|
Es
similar al modelo de red en cuanto a las relaciones y datos, ya
que estos se representan por medio de registros y sus ligas. La
diferencia radica en que están organizados por conjuntos
de árboles en lugar de gráficas arbitrarias.
|
||||||||||||||||||||||||||||
| Modelos físicos de datos. | ||||||||||||||||||||||||||||
|
Se
usan para describir a los datos en el nivel más bajo, aunque
existen muy pocos modelos de este tipo, básicamente capturan
aspectos de la implementación de los sistemas de base de
datos. Existen dos clasificaciones de este tipo que son:
|
||||||||||||||||||||||||||||
| Arquitectura de Dos Capas | Volver | |||||||||||||||||||||||||||
|
Toda
aplicación trata de reflejar parte del funcionamiento del
mundo real, para automatizar tareas que de otro modo serían
llevadas a cabo de modo más ineficiente, o bien no podrían
realizarse. Para ello, es necesario que cada aplicación
refleje las restricciones que existen en el negocio dado, de modo
que nunca sea posible llevar a cabo acciones no válidas.
A las reglas que debe seguir la aplicación para garantizar
esto, se les llaman reglas de negocio, o business rules. Ejemplos
de tales reglas son: no permitir crear facturas pertenecientes
a clientes inexistentes, controlar que el saldo negativo de un
cliente nunca sobrepase cierta cantidad, etc.
|
||||||||||||||||||||||||||||
|
En
realidad, la información puede ser manipulada por muchos
programas distintos; así, una empresa puede tener un departamento
de contabilidad que controle todo lo relacionado con compras,
cobros, etc., y otro departamento técnico, que esté
interesado en relacionar diversos parámetros de producción
con los costes. La visión que ambos departamentos tendrán
de la información y sus necesidades serán distintas,
pero en cualquier caso siempre se deberán respetar las
reglas de negocio. El hecho de que la información sea manipulada
por diversos programas hace más difícil garantizar
que todos respetan las reglas, especialmente si las aplicaciones
corren en diversas máquinas, bajo distintos sistemas operativos,
y están desarrolladas con distintos lenguajes y herramientas.
|
||||||||||||||||||||||||||||
|
En
un esquema cliente-servidor clásico existen dos capas,
el cliente y el servidor: éste está ubicado normalmente
en otra máquina, y suele ser un gestor de base de datos,
como DB2, SQL Server, Oracle, aunque también puede ser
una base de datos más pequeña, como Paradox, Dbase,
etc., que accedemos directamente desde nuestra aplicación
cliente. Los mejores gestores de base de datos relacionales proporcionan
soporte para implementar en ellos bastantes reglas de negocio,
mediante el uso de claves primarias, integridad referencial, triggers,
etc., mientras que sistemas como dBase y otros apenas proporcionan
soporte para reglas de negocio. En los esquemas cliente-servidor
tradicionales, de dos capas, suele ser el gestor de bases de datos
el que proporciona la conectividad, así como capacidades
tan fundamentales como el soporte de transacciones.
|
||||||||||||||||||||||||||||
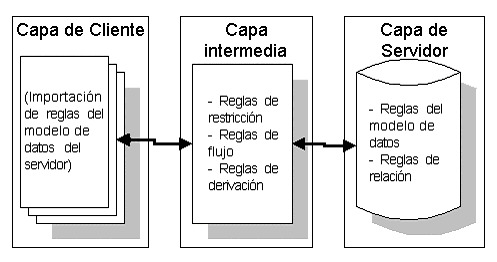
| Arquitectura de Tres Capas. | ||||||||||||||||||||||||||||
|
La
introducción de una capa intermedia puede romper con esto,
al ser necesario un modo de comunicar las aplicaciones cliente
con la aplicación que lleva a cabo las labores de la capa
intermedia, siendo ahora ésta la que se aprovecha de las
capacidades de conectividad, el soporte de transacciones y las
distintas capacidades que proporciona el gestor de base de datos.
Solucionar todos los problemas de conectividad, etc., no es tarea
fácil, y lógicamente debería utilizarse uno
o más productos que solucionen algunos de estos problemas,
basados en DCOM, CORBA y tecnologías similares: es el caso
de MIDAS/OleEnterprise, de Borland, que proporciona protección
contra la caída de servidores, conectividad e importación
de algunas reglas del negocio a los clientes (aunque no soporta
transacciones distribuidas), y de Microsoft Transaction Server
(que proporciona conectividad y transacciones distribuidas, pero
no protección contra caídas de los servidores).
|
||||||||||||||||||||||||||||
| A continuación se presenta el contenido y las especificaciones técnicas de cada capa: | ||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||
| Teoría de Sistema de Base de Datos Relacional en SQL Server | ||||||||||||||||||||||||||||
| ¿Que es un sistema de base de datos? | ||||||||||||||||||||||||||||
|
Un
sistema de Base de Datos
es básicamente un sistema para archivar en computador;
o sea, es un sistema computarizado cuyo propósito general
es mantener información y hacer que esté disponible
cuando se solicite. La información en cuestión puede
ser cualquier cosa que se considere importante para el individuo
o la organización a la cual debe servir el sistema; dicho
de otro modo, cualquier cosa necesaria para apoyar el proceso
general de atender los asuntos de esa organización. Pero
es fundamental para el éxito de su proyecto limitar el
sistema de base de datos, que Ud. quiere diseñar, a un
específico y bien definido conjunto de objetos e interacciones;
lo que le permitirá definir el alcance del sistema. Como
veremos mas adelante no se trata de modelizar "todo"
el mundo sino solo la parte "importante" y "pertinente"
para alcanzar los objetivos funcionales del sistema. Esa parte
del mundo que nos interesa la llamaremos el espacio del problema.
El término modelo de datos se utilizará se utilizará
para significar una descripción conceptual del espacio
del problema, esto incluye la definición de sus entidades,
que son clases de objetos que comparten determinadas características
(por ejemplo un "cliente" es una entidad), dichas características
se las denomina atributos (por ejemplo el "nombre" del
cliente es un atributo de un cliente).
|
||||||||||||||||||||||||||||
|
El
modelo de datos
incluye la descripción de las interrelaciones entre las
entidades y las restricciones sobre dichas relaciones (por ej:
las "facturas de venta" se emiten a nombre de un "cliente"
y esta relación no puede faltar, es decir , no puede haber
una factura que no tenga asignada un cliente.
|
||||||||||||||||||||||||||||
|
La
capa física o esquema físico del
diseño, está constituida por las tablas y vistas
que serán implementadas, y constituye la traslación
del modelo conceptual en una representación física
que pueda ser implementada utilizando el Sistema de Gestión
de Bases de Datos Relacional (SGBDR) a ser empleado, a los fines
de la presente materia el MS-SQL Server 2000. Este esquema no
es mas que la representación del modelo conceptual o lógico
expresado en términos que puedan ser usados para describirlo
al SGBDR.
|
||||||||||||||||||||||||||||
|
A
medida que le vaya explicando al SGBDR como quiere que almacene
los datos, el SGBDR creará los objetos necesarios para
gestionarlos (tablas, vistas, índices, relaciones, etc).
Lo que dará origen a la estructura la base de datos.
|
||||||||||||||||||||||||||||
|
Por
último, llamaremos base de datos a la combinación
de los datos y su estructura. La base de datos incluye, entonces,
a los datos mas las tablas, vistas, procedimientos almacenados,
consultas, y a las reglas que el motor de base datos utilizará
para asegurar el resguardo de los datos.
|
||||||||||||||||||||||||||||
|
El
término base de datos no incluye a la aplicación
la cual consiste de los formularios y los reportes con los que
interactuarán los usuarios, ni incluye la piezas de código
usadas para unir las partes de la aplicación.
|
||||||||||||||||||||||||||||
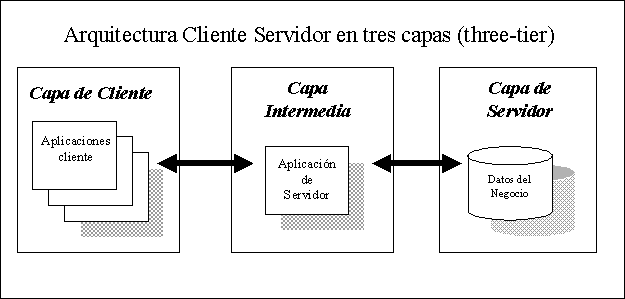
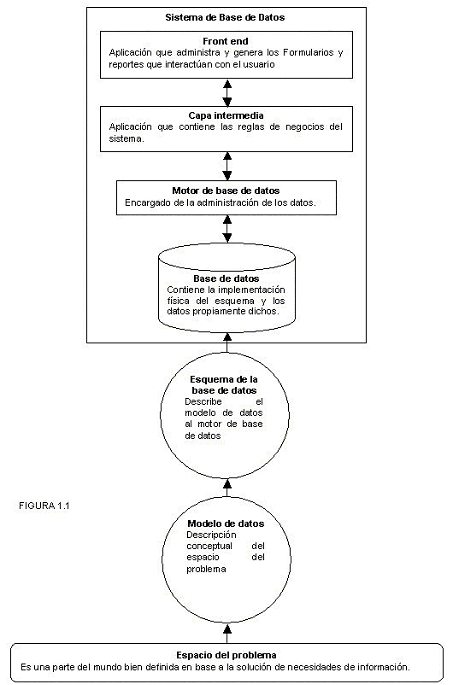
|
En
un modelo de tres capas,
la aplicación que accede a los datos almacenados en una
base de datos y que a la vez interactúa con el usuario
se divide en dos partes: la llamada capa intermedia que contiene
todas las validaciones y las reglas del negocio y es la que interactúa
con la base de datos y el front end que es la que contiene los
formularios y realiza la presentación de los reportes,
interactuando con el usuario final (ver figura 1.1).
|
||||||||||||||||||||||||||||
| El modelo Relacional | Volver | |||||||||||||||||||||||||||
|
El
modelo relacional está basado en una colección de
principios matemáticos desarrollado inicialmente sobre
un conjunto de conceptos teóricos y predicados lógicos.
Esto principios fueron aplicados al campo de los modelos de datos
a finales de los años ´60 por el Dr. E. F. Codd,
investigador de IBM, y publicados por primera vez en 1970.
|
||||||||||||||||||||||||||||
|
El
modelo relacional define el modo en que los datos van a ser representados
(estructura de datos), la forma en que van ser protegidos (integridad
de los datos) y las operaciones que pueden ser aplicadas sobre
ellos (manipulación de datos).
El MS-SQLServer 2000 implementa un modelo relacional de base de datos. En términos generales un sistema de base de datos relacional tiene las siguientes características:
|
||||||||||||||||||||||||||||
|
A
los fines prácticos una relación puede ser considerada
como una tabla, aún cuando al momento de formularse la
teoría intencionalmente se excluyó el término
tabla por tener connotaciones de ordenamiento que no se deben
aplicar al concepto de relación que es mas un conjunto,
que una tabla ordenada. De todos modos y a los fines de la materia
utilizaremos en forma indistinta la denominación de relación
o de tabla.
|
||||||||||||||||||||||||||||
|
Es
importante destacar que el concepto de clausura permite que el
resultado de una operación sobre un relación sea
el dato para otra operación. Por lo que como veremos mas
adelante al resultado de una orden Select se le puede aplicar
otro Select.
|
||||||||||||||||||||||||||||
| Terminología relacional | ||||||||||||||||||||||||||||
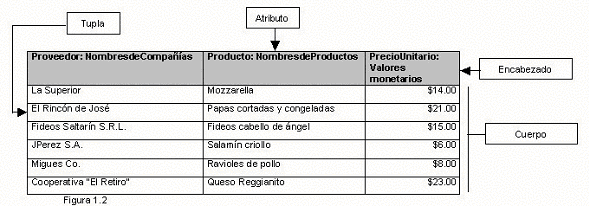
La
Figura 1.2 muestra una relación con los nombres formales
de sus componentes principales
|
||||||||||||||||||||||||||||
|
La
estructura de la figura constituye una relación, donde
cada fila constituye una Tupla. La cantidad de Tuplas en una relación
indica la Cardinalidad de la relación. Cada columna en
la relación es un atributo, y la cantidad de atributos
indica el grado de la relación.
|
||||||||||||||||||||||||||||
|
La
relación se divide en dos secciones el encabezado y el
cuerpo, donde el encabezado contiene la etiquetas de los atributos.
Estas etiquetas constan de dos parte separadas por dos puntos
":" la parte izquierda es la denominación propiamente
dicha del atributo, mientras que la parte derecha configura el
dominio del atributo, que es el conjunto de todos los valores
posibles y legales que puede tomar el atributo en las tuplas (por
ej: el primer atributo de la relación de la figura tiene
como dominio a todas las compañías que existen,
mientras que solo algunas son valores efectivamente incorporados
a la relación).
|
||||||||||||||||||||||||||||
|
El
cuerpo consiste en un conjunto desordenado de cero o más
tuplas, esto indica que las tuplas no tienen un orden intrínseco,
el número de registro no es tenido en cuenta en el modelo
relacional. Por otro lado las relaciones sin tuplas siguen siendo
relaciones. Por último las relaciones son conjuntos donde
cualquier elemento puede ser inequívocamente identificado,
por lo que la relación no permite tuplas duplicadas.
|
||||||||||||||||||||||||||||
En
cuanto a la terminología, en esta parte se utilizó
una lenguaje formal para la definición de los elementos abordados,
a partir de ahora se utilizarán las siguientes equivalencias
de significado:
|
||||||||||||||||||||||||||||
|
Dichas
equivalencias se generan porque al instanciar en la implementación
física el modelo conceptual, se utilizan términos
que corresponden precisamente al modelo físico de implementación
en el SGBDR, en este caso el MS-SQLServer 2000, que utiliza la
terminología Microsoft.
|
||||||||||||||||||||||||||||
| Introducción al diseño de bases de datos | ||||||||||||||||||||||||||||
|
Antes
de que usted pueda desarrollar un modelo lógico de datos,
y subsecuentemente crear una base de datos y los objetos que esta
contiene, usted debe comprender los conceptos fundamentales del
diseño de bases de datos. Además, deberá
estar familiarizado con los componentes básicos de una
base de datos y cómo esos componentes trabajan juntos para
proporcionar un almacenamiento eficaz de los datos y acceso a
aquellos que requieren tipos específicos de datos, en formatos
específicos, desde la base de datos.
|
||||||||||||||||||||||||||||
|
Este
tema presenta los componentes básicos de una base de datos
y la terminología que describe esos componentes. Se discute
la normalización y el concepto de relaciones entre entidades,
dos conceptos que deben integrarse para entender el diseño
de bases de datos relacionales.
|
||||||||||||||||||||||||||||
| Componentes de una base de datos SQL Server | ||||||||||||||||||||||||||||
|
Una
base de datos SQL Server consiste en una colección de tablas
que guardan conjuntos específicos de datos estructurados.
Una tabla (entidad) contiene una colección de filas (tuplas)
y columnas (atributos). Cada columna en la tabla se diseña
para guardar un cierto tipo de información (por ejemplo,
fechas, nombres, montos, o números). Las tablas tienen
varios tipos de controles (restricciones, reglas, desencadenadores,
valores por defecto, y tipos de datos de usuario) que aseguran
la validez de los datos. Las tablas pueden tener índices
(similar a los de los libros) que permiten encontrar las filas
rápidamente. Usted puede agregar restricciones de integridad
referencial a las tablas para asegurar la consistencia entre los
datos interrelacionados en tablas diferentes. Una base de datos
también puede utilizar procedimientos almacenados que usan
Transact-SQL programando código para realizar operaciones
con los datos en la base de datos, como guardar vistas que proporcionan
acceso personalizado a los datos de la tabla.
|
||||||||||||||||||||||||||||
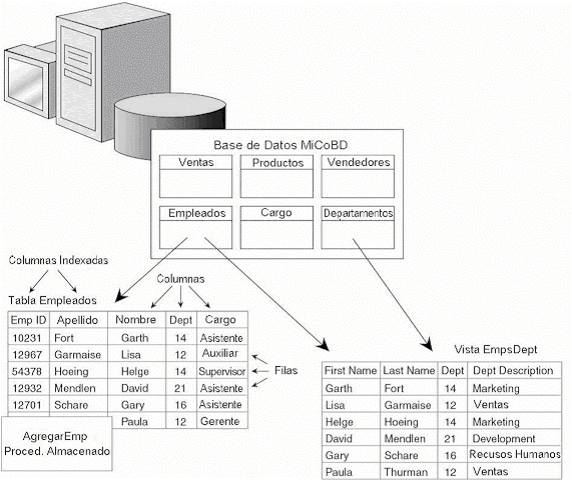
|
Por
ejemplo, suponga que se crea una base de datos llamada MiCoBD
para manejar los datos en su compañía. En la base
de datos MiCoBD, crea una tabla llamada Empleados para guardar
información sobre cada empleado, y la tabla contiene las
columnas EmpID, Apellido, Nombre, Dept, y Cargo. Para asegurar
que nunca dos empleados tengan el mismo EmpID y que la columna
de Dept contiene números sólo válidos para
las secciones en su compañía, usted debe agregar
restricciones a la tabla. Si usted quisiera realizar búsquedas
rápidas para encontrar los datos de un empleado basado
en el ID del empleado, usted definiría índices.
Por cada empleado, se agrega una fila de datos a la tabla Empleados,
para esto usted crea que un procedimiento almacenado llamado AgregarEmp
que se personaliza para aceptar los valores de los datos por un
nuevo empleado y que realiza la operación de agregar la
fila a la tabla Empleados. Se podría necesitar un resumen
departamental de empleados, por lo que usted define una vista
llamada EmpsDept que combina datos de las tablas Secciones y Empleados.
Figura 1.3 muestra las partes de la base de datos MiCoBD.
|
||||||||||||||||||||||||||||
| Normalizar un diseño de base de datos | ||||||||||||||||||||||||||||
|
A
continuación se verá el tema de normalización
desde un punto vista práctico, resaltando aquellos conceptos
útiles y comentando las limitaciones que deben tenerse
en cuenta en el proceso de normalizado de una base de datos.
|
||||||||||||||||||||||||||||
|
Perfeccionar
un diseño de base de datos incluye el proceso de normalización.
Normalizar un diseño lógico de base de datos involucra
usar métodos formales para separar los datos en múltiples
tablas relacionadas. Tener un número mayor de tablas con
pocas columnas es característico de una base de datos normalizada;
mientras que tener pocas tablas con más columnas cada una
es característico de una base de datos no-normalizada.
|
||||||||||||||||||||||||||||
|
Una
normalización razonable mejora a menudo el comportamiento
general del sistema. Cuando se utilizan los índices, el
SQL Server 2000 Query Optimizer (Optimizador de Consultas de SQL
Server) es muy eficiente al seleccionar interrelaciones entre
las tablas.
|
||||||||||||||||||||||||||||
|
Un
aumento de la normalización produce una mayor cantidad
y complejidad de combinaciones entre las tablas requeridas para
recuperar los datos. Demasiadas combinaciones complejas entre
varias tablas puede deteriorar el rendimiento en las consultas.
Una normalización razonable debería incluir la mínima
cantidad de consultas habituales posible que involucren más
de cuatro tablas relacionadas.
|
||||||||||||||||||||||||||||
|
Una
base de datos que se usa principalmente para soporte de decisión
(al revés de una base de datos operacional que realiza
tareas de actualización de datos) podría no tener
actualizaciones redundantes y podría ser más entendible
y eficaz para las consultas si el diseño no se normaliza
totalmente. No obstante, tener datos no-normalizados es el error
de diseño más común en aplicaciones de base
de datos más que tener datos demasiado normalizados. Empezar
con un diseño completamente normalizado y a partir de allí
desnormalizar selectivamente algunas tablas por razones específicas
de rendimiento de las consultas es una buena estrategia.
|
||||||||||||||||||||||||||||
|
A
veces el diseño de la base de datos lógico ya está
definido, tal el caso de una base de datos existente, y el rediseño
total no es factible. Pero aún entonces, podría
ser posible normalizar una tabla grande selectivamente en varias
tablas más pequeñas. Si la base de datos es accedida
a través de los procedimientos almacenados, este cambio
del esquema podría tener lugar sin afectar las aplicaciones.
Si no, podría ser posible crear una vista que esconde de
las aplicaciones el cambio del esquema.
|
||||||||||||||||||||||||||||
| Lograr una base de datos bien diseñada | ||||||||||||||||||||||||||||
|
En
la teoría de diseño de base de datos relacionales,
las reglas de normalización identifican ciertos atributos
que deben estar presentes o ausentes en una base de datos bien
diseñada. Estas reglas pueden ponerse bastante complicadas
y pueden ir más allá del alcance del presente. De
todos modos, hay algunas reglas que pueden ayudarlo a lograr un
diseño de la base de datos correcto. Una tabla debe tener
un identificador, debe guardar datos para sólo un solo
tipo de entidad, debería evitar columnas que acepten valores
nulos, y no debe tener valores o columnas repetidas.
|
||||||||||||||||||||||||||||
| Una Tabla debe Tener un Identificador | ||||||||||||||||||||||||||||
|
La
regla fundamental de la teoría del diseño de base
de datos es que cada tabla debe tener un identificador de las
filas, que es una columna o un conjunto de columnas que toman
valores únicos para cada registro de la tabla. Cada tabla
debe tener una columna de ID, y ningún registro puede compartir
el mismo valor de ID con otro. La columna (o columnas) que sirve
como identificador único de la fila para una tabla constituye
la clave primaria de la tabla.
|
||||||||||||||||||||||||||||
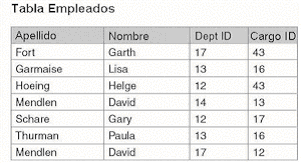
|
En
la Figura 1.4, la tabla Empleados no incluye una columna que identifica
unívocamente cada fila dentro de la tabla. Fíjese
que el nombre de David Mendlen aparece dos veces. Al no haber
ningún identificador único en esta tabla, no hay
ninguna manera de distinguir fácilmente una fila de otra.
Esta situación podría ser un problema, más
aún, si ambos empleados trabajaron en la misma sección
y tienen el mismo tipo de trabajo.
|
||||||||||||||||||||||||||||
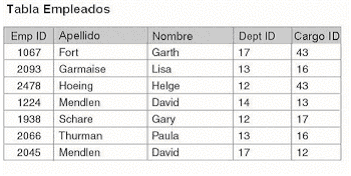
|
Usted
puede normalizar la tabla agregando una columna que singularmente
identifique cada fila, como se muestra en la Figura 1.5. Fíjese
que cada instancia de David Mendlen tiene un único valor
de EmpID.
|
||||||||||||||||||||||||||||
|
Una
Tabla debe Guardar Datos para un Solo Tipo de Entidad
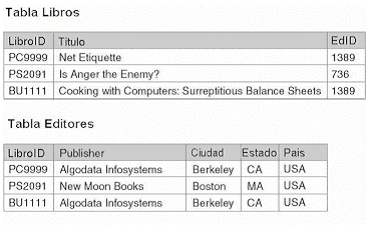
Intentar guardar demasiada información en una tabla puede afectar la administración eficaz y fiable de los datos en la tabla. Por ejemplo, en la Figura 1.6, la tabla Libros incluye información sobre cada editor de libros.
|
||||||||||||||||||||||||||||
|
Aunque
es posible tener columnas que contienen información para
el libro y su editor en la misma tabla, este diseño lleva
a varios problemas. La información del editor debe agregarse
y debe guardarse redundantemente para cada libro publicado por
un editor dado. Esta información usa espacio extra de almacenamiento
en la base de datos. Si la dirección del editor cambia,
el cambio debe realizarse en todos los registros de libros de
ese editor. Además, si el último libro de un editor
es eliminado de la tabla Libros, la información de ese
editor se pierde.
|
||||||||||||||||||||||||||||
|
En
una base de datos normalizada, se guardaría la información
sobre los libros y editores en por lo menos dos tablas: una para
los libros y una para los editores (como se muestra en Figura
1.7).
|
||||||||||||||||||||||||||||
|
La
información sobre el editor tiene que ser grabada sólo
una vez y quedar vinculada a cada libro de ese editor. Si la información
del editor cambia, debe cambiarse en sólo un lugar, y la
información del editor estará allí aún
cuando el editor no tenga ningún libro en la base de datos.
|
||||||||||||||||||||||||||||
| Una Tabla debe Evitar Columnas que acepten valores nulos | ||||||||||||||||||||||||||||
|
Las
tablas pueden tener columnas definidas para permitir valores nulos.
Un valor nulo indica que el registro no tiene valor por ese atributo.
Aunque puede ser útil permitir valores nulos en casos aislados,
es mejor usarlos muy poco porque ellos requieren un manejo especial
con el consiguiente aumento de la complejidad de las operaciones
de datos. Si tiene una tabla que tiene varias columnas que permiten
valores nulos y varias de las filas tienen valores nulos en dichas
columnas, debería considerar poner estas columnas en otra
tabla vinculada a la tabla primaria. Guardar los datos en dos
tablas separadas permite que la tabla primaria sea simple en su
diseño pero a la vez mantener la capacidad de almacenar
información ocasional.
|
||||||||||||||||||||||||||||
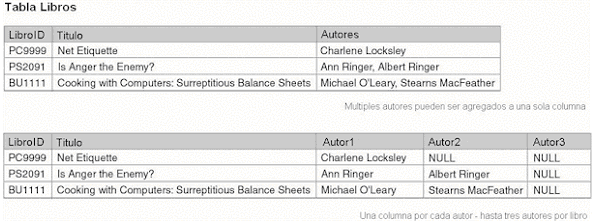
| Una Tabla no Debe tener Valores o Columnas Repetidas | ||||||||||||||||||||||||||||
|
Una
tabla no debe contener una lista de valores para un pedazo específico
de información. Por ejemplo, suponga que usted quiere consultar
los títulos de libros y sus autores. Aunque la mayoría
de los libros podrían tener sólo un autor, muchos
de ellos podrían tener dos o más. Si hay sólo
una columna en la tabla Libros para el nombre del autor, esta
situación presenta un problema. Una solución es
guardar el nombre de ambos autores en una columna, pero mostrar
una lista de autores individuales sería entonces difícil.
Otra solución es cambiar la estructura de la tabla para
agregar otra columna para el nombre del segundo autor, pero esta
solución guarda sólo dos autores. Debería
agregarse otra columna si algún libro tiene tres autores.
|
||||||||||||||||||||||||||||
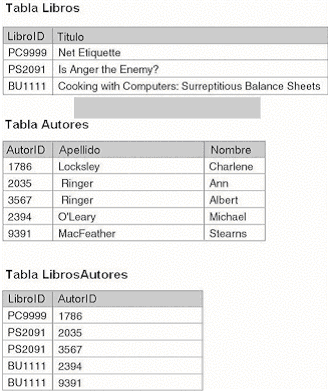
|
Si
usted encuentra que necesita guardar una lista de valores en una
sola columna o si tiene columnas múltiples para una sola
pieza de datos (Autor1, Autor2, y así sucesivamente), debe
considerar poner los datos duplicados en otra tabla con un vínculo
a la tabla primaria. En el caso de la tabla Libros, usted podría
crear una tabla primaria adicional para los autores y luego crear
una tercera tabla que vincule los libros a sus autores y almacene
los valores repetidos, como se muestra en la Figura 1.9. Este
diseño habilita cualquier número de autores para
un libro sin modificar la definición de la tabla y no desperdicia
espacio libre para almacenar libros que tienen un solo autor.
|
||||||||||||||||||||||||||||
| Relaciones entre entidades | ||||||||||||||||||||||||||||
|
En
una base de datos relacional, las relaciones entre entidades ayudan
a prevenir datos redundantes. Una relación entre entidades
trabaja vinculando datos de dos tablas a través de columnas
clave, que generalmente tienen el mismo nombre en ambas tablas.
En la mayoría de los casos, la relación entre entidades
vincula la clave primaria de una tabla que proporciona a un identificador
único para cada fila con una entrada en la clave foránea
de la otra tabla. Se discuten claves primarias y las claves foráneas
en más detalle en Integridad de los Datos."
|
||||||||||||||||||||||||||||
|
Hay
tres tipos de relaciones entre las tablas: uno-a-uno, uno-a-muchos,
y muchos-a-muchos. El tipo de relación depende de cómo
se definen las columnas relacionadas.
|
||||||||||||||||||||||||||||
| Relaciones entre tablas uno-a-uno | ||||||||||||||||||||||||||||
|
En
una relación uno-a-uno, una fila en tabla A no tiene más
de una fila vinculada en tabla B (y viceversa). Una referencia
uno-a-uno se crea si las dos columnas relacionadas son claves
primarias o tienen restricción de unicidad. Este tipo de
referencia no es común, sin embargo, porque la información
relacionada de esta manera normalmente estaría en una sola
tabla.
|
||||||||||||||||||||||||||||
| Relaciones entre tablas uno-a-muchos | ||||||||||||||||||||||||||||
|
Una
relación uno-a-muchos es el tipo más común
de relación entre entidades. En este tipo de relación,
una fila en la tabla A tiene muchas filas vinculadas en la tabla
B, pero una fila en la tabla B tiene una única fila vinculada
en la tabla A. Por ejemplo, las tablas Editores y Título
mencionadas previamente tienen una relación uno-a-muchos.
Cada editor produce muchos títulos, pero cada título
tiene un solo editor. Una relación uno-a-muchos se crea
si solo una de las columnas relacionadas es una clave primaria
o tiene una restricción de unicidad.
|
||||||||||||||||||||||||||||
| Relación entre tablas muchos-a-muchos | ||||||||||||||||||||||||||||
|
En
una relación muchos-a-muchos, una fila en tabla A tiene
muchas filas vinculadas en tabla B (y viceversa). Se puede crear
tal relación definiendo una tercera tabla, llamada tabla
de unión cuya clave primaria consiste en las claves foráneas
de ambas tablas A y B. En las Figuras 1.8 y 1.9, usted vio cómo
la información del autor puede separarse en otra tabla.
La tabla Libros y la tabla Autores tienen una relación
muchos-a-muchos. Cada una de estas tablas tiene una relación
uno-a-muchos con la tabla de LibrosAutores que sirve como la tabla
de la unión entre las dos tablas primarias.
|
||||||||||||||||||||||||||||
| Resumen | ||||||||||||||||||||||||||||
|
Una
base de datos SQL Server consiste en una colección de tablas
que guardan un conjunto específico de datos estructurados.
Una tabla contiene una colección de filas y columnas. Cada
columna en la tabla se diseña para guardar un cierto tipo
de información (por ejemplo, fechas, nombres, montos, o
números). El diseño lógico de la base de
datos, incluyendo las tablas y las relaciones entre ellas, es
el corazón de una base de datos relacional optimizada.
Perfeccionar un diseño de base de datos incluye el proceso
de normalización. Normalizar un diseño lógico
de base de datos lógico involucra usar métodos formales
para separar los datos en múltiples tablas relacionadas.
A medida que la normalización aumenta, incrementa el número
y la complejidad de los vínculos que son necesarios para
recuperar los datos. Las reglas de normalización identifican
ciertos atributos que deben estar presentes o ausentes en una
base de datos bien diseñada. Las tablas en una base de
datos normalizada deben tener un identificador, deben guardar
sólo datos para un solo tipo de entidad, deben evitar columnas
que acepten valores nulos, y no deben tener valores o columnas
repetidos. Usted puede crear relaciones entre sus tablas en un
diagrama de la base de datos y mostrar cómo se vinculan
las columnas en una tabla a las columnas de otra tabla. En una
base de datos relacional, las relaciones ayudan a prevenir datos
redundantes. Una relación trabaja vinculando datos de las
columnas, generalmente columnas clave que tienen el mismo nombre
en ambas tablas. Hay tres tipos de relaciones entre las tablas:
uno-a-uno, uno-a-muchos, y muchos-a-muchos. El tipo de relación
entre tablas depende de cómo usted define las columnas
relacionadas.
|
||||||||||||||||||||||||||||
| Desarrollar el Modelo Lógico de Datos | ||||||||||||||||||||||||||||
| Identificar Entidades y Sus Atributos | ||||||||||||||||||||||||||||
|
Cuando
se recogen los requisitos del sistema para al diseño de
la base de datos, uno de los pasos que se realizan es el de definir
los tipos de datos que contendrá la base de datos. Pueden
separarse estos tipos de datos en categorías que representan
una división lógica de información. En la
mayoría de los casos, cada categoría de tipo de
dato se traduce en un objeto tabla dentro de la base de datos.
Hay normalmente, un conjunto de objetos primarios, y después
de que ellos son identificados, surgen los objetos relacionados.
|
||||||||||||||||||||||||||||
|
Por
ejemplo, en la base de datos Editores, uno de los objetos primarios
es la tabla Titulos. Uno de los objetos relacionado a la tabla
Títulos es la tabla de RoyAgenda que proporciona información
sobre la agenda de royalties asociada con cada libro. Otro objeto
es la tabla TituloAutor que vincula a los autores con los libros.
|
||||||||||||||||||||||||||||
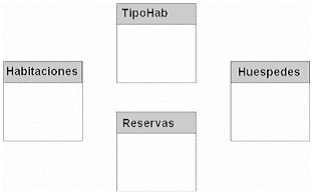
|
Usando
las categorías de datos definidas en los requisitos del
sistema, se puede empezar a crear un mapa del objeto tabla dentro
de la nueva base de datos. Por ejemplo, suponga que usted está
diseñando una base de datos para el sistema de reservaciones
de un hotel. Durante el proceso de recolección de requisitos
de sistema, identifica varias categorías de datos, incluido
los cuartos, huéspedes, y reservaciones. Como resultado,
agrega tablas a su diseño de la base de datos que representan
a cada una de estas categorías, como se muestra en la Figura
1.10
|
||||||||||||||||||||||||||||
|
Al
identificar las reglas comerciales para este sistema, usted determinó
que el hotel tiene ocho tipos de cuartos y que los huéspedes
regulares prefieren un cierto tipo de cuarto. Como resultado,
tanto la tabla Habitaciones como la tabla Huespedes deberán
incluir un atributo de tipo de cuarto. Usted decide crear una
tabla para los tipos del cuarto, como se muestra en Figura 1.11.
|
||||||||||||||||||||||||||||
|
Ahora,
la tabla Habitaciones y la tabla Huespedes referencian a la tabla
TipoHab sin tener que repetir una descripción del cuarto
para cada cuarto y cada huésped. Además, ante un
cambio en los tipos de cuarto, usted puede actualizar la información
en un solo lugar, en lugar de tener que actualizar múltiples
tablas y archivos.
|
||||||||||||||||||||||||||||
|
Antes
de que usted pueda completar el proceso de definir objetos de
la tabla dentro de la base de datos, debe definir las relaciones
entre las tablas. Siempre que identifique una relación
muchos-a-muchos, tendrá que agregar una tabla de unión.
Se discuten relaciones con más detalle adelante en este
tema.
Después de que usted ha definido todas las tablas que puede definir a estas alturas, puede definir las columnas (atributos) para esas tablas. De nuevo, usted estará tomando esta información directamente de los requisitos del sistema en los que identificó qué tipos de datos deben ser incluidos en cada categoría de información. |
||||||||||||||||||||||||||||
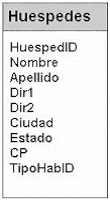
|
Usando
el ejemplo de base de datos del hotel, suponga que determinó
durante el proceso de recolección de requisitos del sistema
que la categoría Huespedes debe incluir información
la siguiente información sobre los huéspedes: nombre,
apellido, dirección, número de teléfono,
y preferencias del cuarto. Como resultado, usted planea agregar
columnas a la tabla de los Huespedes para cada uno de estos tipos
de información. Usted también planea agregar un
identificador único para cada huésped, tal como
con cualquier entidad normalizada. La Figura 1.12 muestra la tabla
Huespedes con todas las columnas que contendrá la tabla.
|
||||||||||||||||||||||||||||
| Identificar Relaciones Entre las Entidades | ||||||||||||||||||||||||||||
|
Después
de que ha definido las tablas y sus columnas, usted debe definir
las relaciones entre las tablas. A través de este proceso,
podría descubrir que necesita modificar el diseño
que ha creado.
|
||||||||||||||||||||||||||||
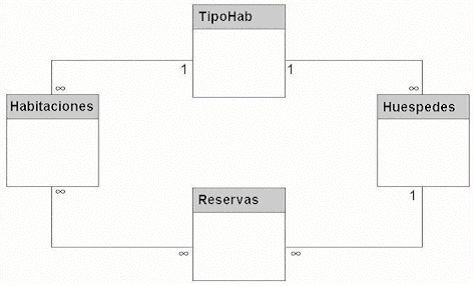
|
Empiece
escogiendo una de las tablas primarias y seleccionando las entidades
que tienen relaciones con esa tabla. Siguiendo con el ejemplo
del hotel, asuma que los requisitos del sistema indican que todas
las reservaciones deben incluir cuarto e información del
huésped. Los cuartos, huéspedes, y reservaciones
son las categorías de datos. Como resultado, usted puede
deducir que una relación existe entre los cuartos y reservaciones
y entre los huéspedes y reservaciones. La Figura 5.4 muestras
las relaciones entre estos objetos. Una línea que conecta
las dos tablas significa una relación. Advierta que una
relación también existe entre la tabla Habitaciones
y la tabla TipoHab y entre la tabla Huespedes y la tabla TipoHab.
|
||||||||||||||||||||||||||||
|
Una
vez que establece que una relación existe entre las tablas,
usted debe definir el tipo de relación. En la Figura 1.13,
cada relación (línea) es marcada a cada extremo
(donde conecta a una tabla) con el número 1 o con un símbolo
de infinito (8). El 1 se refiere al lado uno de una relación,
y el símbolo de infinito se refiere al lado muchos de una
relación uno-a-muchos. Algunos autores también las
llaman relaciones 1:N.
|
||||||||||||||||||||||||||||
|
Para
determinar los tipos de relaciones que existen entre las tablas,
usted debe mirar los tipos de datos que cada tabla contiene y
los tipos de conexiones entre ellos. Por ejemplo, una relación
existe entre la tabla Huespedes y la tabla Reservas. La relación
existe porque los huéspedes son parte de la información
que se recaba cuando se registra una reservación. Según
las reglas comerciales, un huésped puede hacer una o más
reservaciones, pero cada reservación grabada puede incluir
solo el nombre de un huésped, normalmente la persona que
está haciendo la reservación. Como resultado, una
relación uno-a-muchos existe entre las dos tablas: un huésped,
una o muchas reservaciones.
|
||||||||||||||||||||||||||||
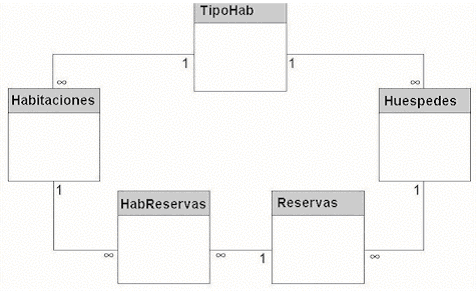
|
Una
relación también existe entre la tabla Reservas
y la tabla Habitaciones. Según las reglas comerciales,
una reservación puede solicitar uno o más cuartos,
y un cuarto puede ser incluido en una o más reservaciones
(en fechas diferentes). En este caso, existe una relación
muchos-a-muchos: muchas reservaciones a muchos cuartos. En un
diseño de base de datos normalizado, sin embargo, relaciones
muchos-a-muchos deben ser modificadas agregando una tabla de unión
y creando una relación uno-a-muchos entre cada tabla original
y la tabla de unión, como se muestra en la Figura 1.14.
|
||||||||||||||||||||||||||||
| Identificar Restricciones sobre los Datos | ||||||||||||||||||||||||||||
|
A
estas alturas del proceso de diseño de la base de datos,
usted debería tener definidas las entidades, sus atributos,
y las relaciones entre entidades. Ahora, usted debe identificar
las restricciones sobre los datos que se guardarán en las
tablas. El mayor trabajo ya fue completado cuando usted identificó
las reglas comerciales al momento de recoger los requisitos del
sistema. Como se vio, las reglas comerciales incluyen todo las
restricciones en un sistema, incluida la integridad de los datos
y la seguridad del sistema. Para esta fase del proceso de diseño,
su enfoque se centrará en las restricciones sobre los datos.
Usted tomará las reglas comerciales relacionadas a los
datos y las refinará y organizará. Debe intentar
organizar las restricciones en base a los objetos que creó
en la base de datos, y formularlas de modo que se refieran a ellos.
|
||||||||||||||||||||||||||||
|
Volviendo
al diseño de la base de datos de la Figura 1.14, suponga
que una de las reglas comerciales indica: "Un registro de
huésped puede, pero no es obligatorio, incluir una preferencia
por uno de los tipos de cuarto predefinidos pero no puede incluir
ninguna otra preferencia de tipo de cuarto." Al definir las
restricciones sobre los datos, usted debe referenciar las tablas
y columnas pertinentes y dividir la regla comercial de modo que
cada restricción esté contenida en una instrucción
simple:
|
||||||||||||||||||||||||||||
|
En
cuanto sea posible, usted debe organizar las restricciones sobre
los datos según las tablas y sus columnas. En algunos casos,
una restricción se aplica al conjunto de una tabla, a más
de una tabla, a una relación entre las tablas, o a la seguridad
de los datos. En estos casos, intente organizar las restricciones
de modo que sea lógica y más pertinente al proyecto.
La meta de identificar las restricciones sobre los datos es tener
un mapa claro del camino para cuando se creen los objetos de la
base de datos y sus relaciones que fuerce la integridad de los
datos
|
||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||